
This is an edited transcript from an Oticon webinar on AudiologyOnline. Download supplemental course materials.
Learning Objectives
- Participants will be able to describe the range of variability in the effects of severe and profound hearing loss.
- Participants will be able to explain how nonlinear signal processing can be individually activated and adjusted to meet the individual needs of the patients in this range of loss.
- Participants will be able to discuss how to develop a decision making strategy concerning the use and adjustment of frequency composition for individual patients.
Introduction
Dr. Don Schum: Oticon has a history of creating excellent solutions for patients with severe-to-profound hearing loss. With the release of Oticon Dynamo, Sensei Super Power, and the Plus Power products in our performance line categories, we have again raised the bar in the way we approach treating patients with significant degrees of hearing loss.
In order to create good solutions for patients in this hearing loss range, you have to understand the condition that you are treating. Hearing care is health care. Any time you are dealing with hearing loss, you are dealing with a change in a complex physiological mechanism in the body. It is important to understand the nature of the disorder before we go about attempting to create solutions and apply them. This seminar will address what we understand as a profession and as a supplier about severe-to-profound hearing loss and how we approach treating these patients.
Etiology of Hearing Loss
Whether talking about children or adults, it is important to understand the etiology of the hearing loss. Every professional in our field will acknowledge that the audiogram is not a complete description of hearing impairment. While it is important to know how much threshold change there is, it is also very important to understand at a deeper level what has changed about the auditory system in patients with this amount of hearing loss. One of the best places to start that discussion is to talk about the nature of severe-to-profound sensorineural hearing loss, where it comes from, and what effects it has on the body. It is essential for all professionals to think about what has changed in the peripheral auditory system.
Thresholds
We get tied closely to thresholds, and thresholds are well predicted in most patients with hearing loss by a simple model of hearing loss that includes discussion of outer and inner hair cells and how the loss of those change sensitivity and the size of the dynamic range. Some of the etiologies of severe hearing loss include congenital loss, viral infections, meningitis, ototoxicity, sudden or idiopathic loss, or long-standing Meniere’s disease. These are more complex than just hair cell issues.
The understanding of how loss of hair cell function changes thresholds is important because it is involved in most cases of hearing loss, but it does completely describe what is going on. For example, in congenital losses, one of the most common causes of genetically-related congenital hearing loss is Connexin 26. It is a loss of a protein that is involved in the communication from cell to cell. That changes the physiology in a very specific way.
Some of the viral effects of cytomegalovirus (CMV) or viruses that are contracted by adults that lead to hearing loss can be different in terms of what changes in the way the inner ear is working. Meningitis can cause ossification within the inner ear, which changes the physiology in one particular way. Ototoxicity patterns can be unique and variable. With sudden or idiopathic hearing losses, you do not always know what happened or how the inner ear has changed. Patients who have had Meniere's disease over the years may have lost thresholds down into the severe range or sometimes even beyond. Furthermore, they have had pressure changes across the membranes of the inner ear, which could have resulted in tears, patching, regrowth or scar tissue.
Physiology: Hair Cells
In each of these different etiologies, there is a different effect on the physiology. As healthcare providers, it is important for us to understand what has changed about the body, because that is what we are trying to help. When we talk about the nature of severe-to-profound hearing loss, starting with the etiology is a very good place to start.
There is no doubt that hair cells are involved in hearing loss. The most typical pattern of loss that would lead to significant hearing loss is the relationship between inner hair cells and outer hair cells. As we know, there are three rows of outer hair cells and one row of inner hair cells. The inner hair cells carry the information out of the periphery into the central auditory system or at least to the VIIIth nerve, and then that sends the information up to the brain.
The function of the outer hair cells is to improve the sensitivity of the inner hair cells. The inner hair cells themselves are not particularly sensitive to soft sounds, but they become sensitive to soft sounds through active processes that are mediated by the outer hair cells which allow them to detect very small mechanical movements in the fluids in the inner ear caused by soft sounds. For most hearing losses in the mild to moderate range, the outer hair cells have been lost or damaged. Most of the inner hair cells tend to remain intact. That would predict a raise in threshold because the outer cells were involved in improving the sensitivity of the inner hair cells, but once you get to a moderate input level then you have enough power to start stimulating inner hair cells. That model of sensorineural hearing loss has worked well for the last couple of decades because it has helped us to understand what is necessary to correct for a reduced dynamic range. It also helps us understand gain and compression.
In some unusual cases, hair cell damage can occur in just the inner hair cells where the outer hair cells are undisturbed. We see some scans where inner hair cells are disrupted. Some are fused together. Even if you look at sensorineural hearing loss from the perspective of hair cell configuration, we see cases where the damage patterns become very different than what we typically would expect from our simplified model of sensorineural hearing loss. The inner ear is a complex, highly intricate, calibrated electrochemical mechanical system.
There are many processes orchestrating at once. There is a mechanical movement of the fluids throughout the inner ear. A certain fluid chemistry is necessary for the hair cells to fire, and then that firing has to be transmitted into a neural code that is sent up to the central auditory system. These things have to work correctly. In physiology, think back to the stria vascularis. Remember that it supplies the blood to the inner ear, which is critical for proper performance. If there are any disorders that disrupt blood flow in the human body, one of the effects can easily be hearing loss if blood flow is also restricted to the inner ear. The structures, which are dependent upon blood flow, become under-nourished. Remember that there is perilymph and endolymph fluids within these cavities. The chemical composition of those fluids are different, with a perfect balance of sodium and potassium required to make the system work.
One of the most common causes of hearing loss, especially childhood congenital hearing loss, is a genetic condition called Connexin 26. Connexin 26 is a loss of a protein that helps cells communicate with each other. The outer hair cells and their supporting cells along with the inner hair cells and their supporting cells have to communicate in order for the hair cells to fire properly. As you know, a hair cell fires when it bends, but in order for this to happen, the chemical composition around it has to be appropriate, namely the balance of sodium and potassium. When that chemical balance is off, the hair cell cannot do its job. In Connexin 26, the potassium pump is dysfunctional.
In this pump, a flow of potassium goes through the hair cells, back out through the stria vascularis, back into the perilymph, and then down through the hair cells for them to fire again. This process happens as a sort of recycling. In Connexin, the cells cannot communicate with each other because of the loss of this protein, so the potassium gets out of balance because it is not recycled. The hair cells are available, but they cannot fire because the chemical bath in which they sit is not properly aligned. This is a good example of severe hearing loss where counting hair cells and looking for dead zones does not apply. This is a reminder of the complexity of the physiology of the inner ear and how that can be disrupted.
Audiograms
When considering severe hearing loss, we typically talk about people who have significant hearing loss across the frequency range. Sometimes in these audiograms we see a slope to the hearing loss, but generally we observe a disorder across the hearing loss range. One of the big topics in treating patients with severe-to-profound hearing loss is frequency lowering, where information that might be inaudible or unusable in the high frequencies is moved down to the mid frequencies.
It reminds me that although you can make information maybe more audible in the mid frequencies than in the high frequencies, it does not necessarily mean that the ear is working well there either. Whatever is causing the hearing loss may also be causing dysfunction in the mid and low frequencies as well. The idea of making things audible and above threshold does not necessarily mean it is in the part of the auditory system that is working particularly well.
When looking at audiograms, we may also see a certain amount of asymmetry, even small. It is a reminder that the change in physiology is likely more complex in patients with these audiograms than other audiograms.
One of the hallmarks of patients with severe-to-profound hearing loss is the amount of variability from patient to patient in performance. All patients with sensorineural hearing loss have variability either in word recognition or speech perception testing or on basic psychoacoustic testing. That variability is significantly greater than a test group of patients with normal hearing. If you compare different groups of patients with sensorineural hearing loss, the variability starts to get very large when you move into the severe hearing loss range.
Speech Performance and Perception
One of the basic measures that can always be used is word recognition testing, because it is the sum of all the changes in the physiology in the ear, and how the changes in psychoacoustic performance are going to end up affecting speech perception. Arthur Boothroyd (1993) described three dimensions to the hearing loss. One is the threshold, one is the upper limit of usable hearing or the discomfort level, and the third is the dynamic range and how useful that is.
Just because you can make speech audible to a patient does not mean that the ear is good enough to make proper use of that signal. Remember, what it takes to get a threshold in terms of psychoacoustic integrity is far less complicated than what it takes to be able to process a speech signal. It is a good reminder that the audiogram does not necessarily tell you the quality of the hearing above threshold.
Dr. Pam Souza (2009) evaluated the performance of patients with severe hearing loss using speech recognition performance in background noise. It is a signal-to-noise-ratio base test, so lower scores are better. She compared a group of patients with mild to moderate hearing loss to patients with severe hearing loss. Almost all of the patients with mild to moderate hearing loss were within about 10 dB signal-to-noise ratio and were reasonably close to normal performance in noise.
When compared to the group with severe hearing loss, the mild to moderate group had significantly less variability. Performance differences from patient to patient to patient in the severe hearing loss group can be varied. You see the same thing if you look at something even more simple, like speech understanding performance in quiet.
Other data out of Holland (Lamore, Verweij, & Brocaar, 1990) looked at maximum word recognition in quiet for patients with different amounts of average hearing loss. Up to about 60 to 70 dB of hearing loss, most patients score at 80% correct or above, which is what most audiologists would expect. Once you get above 75 or 80 dB of hearing loss, you start to see a tremendous amount of variability. Some patients had very good performance in quiet, even though they have a lot of threshold loss, but some had very significantly reduced performance in quiet.
The types of performance you can expect will vary depending on the quality of the remaining hearing. Some simple tasks, like rhythm and intonation patterns, which are a gross psychoacoustic skill, can be maintained to a very great degree for patients with this amount of hearing loss, but when you get down to something more precise, like consonant perception which is a greater psychoacoustic challenge to the system, then you see performance, on average, is poorer.
Physical Aspects of Speech
The on-going speech waveform is comprised of varying peaks and troughs, which correspond to phonemes. Most individuals with normal hearing, and even those with mild to moderate hearing loss, still have enough frequency resolution to distinguish between the various phonemes and resolve spectral peaks that distinguish those sounds.
The phoneme /sh/ is a moderate level unvoiced fricative in the higher frequencies, and it is defined by a spectral peak in the mid to high frequencies, between 2000 and 3000 Hz. Many patients with severe and severe-to-profound hearing loss lose this frequency resolution ability where they can no longer tell precise frequency differences between sounds as well as a person with less hearing loss.
The spectral peaks become more difficult to distinguish higher in the frequency range, as well as if the sound is brief. It has been observed that patients with severe hearing loss often are more tuned in to the envelope of the speech signal, which is the ongoing energy flow in the signal over time, not the precise frequency differences. That cue is available even to people with normal hearing, but we typically do not use that to a high degree for identification because we do not need to. Frequency information is a stronger source of information. However, when that is degraded, you might be tied to a secondary cue like the overall envelope of the speech signal. The problem is that the non-linear approach typically used with patients with severe and severe-to-profound hearing loss is multi-channel, fast-acting compression.
The problem with fast-acting non-linear processing is that every time the signal level drops, it wants to turn up gain. Every time the signal level starts to go up, it wants to turn gain down. What we are telling the system to do is make the envelope fluctuations in the speech signal less, to lessen the changes from peak to valley. But for patients with severe and severe-to-profound hearing loss, you are telling the hearing aid to take away one of the primary cues that this patient uses in order to extract information from the speech signal. It became quite clear why patients with severe or severe-to-profound hearing loss were not responding well to early attempts to use non-linear processing.
If you are going to treat someone with severe hearing loss or severe-to-profound hearing loss using multi-channel non-linear compression, it is important to decide how you are going to do that. There is a huge advantage to multi-channel non-linear processing for someone with severe hearing loss; you can do a better job of ensuring audibility across a broader frequency range by using this approach. If you use the wrong kind of non-linear approach, however, you can run into a situation where you are not giving them enough information. That is why these patients often gravitate towards older types of technology, especially power linear hearing aids.
Amplified Speech must be Audible and Usable
When you fit hearing aids, what does it take to get the most out of the speech signal for the patient? This answer depends on several factors. In this case, it will vary depending on how much hearing loss the patient has, and more specifically, what the remaining resolution of the auditory system is.
Amplified speech must be both audible and usable. We have gotten into a habit over the last decade with the use of real-ear verification techniques that as long as you make the speech signal audible, you have done everything required in the fitting. While this is an important step in the hearing and fitting process, it is not the end of the story. It is not a guarantee that the signal is usable to the patient.
In the cases of severe hearing loss, you want to reflect the knowledge you have about their hearing loss in the way you go about creating your non-linear approach. You want to have an approach that allows you to maintain the modulation depth of the envelope. We can achieve that with Oticon’s non-linear process approach called Speech Guard E.
Speech Guard E
Speech Guard E is used in our mid- and high-end hearing aids. It processes the signal in a way that maintains as many of the details in the speech waveform as possible. It is unique in the industry because it determines the amount of gain that is applied to the signal at any moment in time based on two different measures of the input level that are averaged differently over time. One takes a long-term look at the signal, and another looks moment to moment. The goal is to set the gain in the hearing aid at any moment in time based on the overall long-term level of the speech signal.
Those moment-to-moment differences in the speech signal carry a lot of information. If someone is talking at the same level over time, you do not want the hearing aid to be changing gain on a moment to moment basis. It is unnecessary and it will destroy signal information in the signal.
Speech Guard E will typically maintain the ongoing envelope. If you change on a moment-to-moment basis, like with fast acting compression, you are changing the modulation pattern of the envelope. However, if you can maintain a constant gain parameter in each frequency channel, you can do a much better job of maintaining the speech envelope. With Speech Guard, you can maintain the same amount of envelope depth in the output as you see in the input signal.
If this is a primary cue that someone with severe loss is going to use, then it is a technology that we believe makes more sense for patients than traditional fast-acting compression. Speech Guard allows you to use whatever gain and compression parameters you want; it manages those quite effectively in our systems.
When creating a solution for patients with severe and severe-to-profound hearing loss, know how you want to calculate gain and compression and how you want to set up your input/output function in the hearing aid. In almost all cases of severe to profound hearing loss, you will be dealing with a restricted dynamic range. You need to know if you can fit everything in that range or if you will have to make some compromises. Traditional non-linear amplification using fast-acting compression to cram everything into that remaining dynamic range will destroy information in the speech signal that the person could otherwise use. You have to make smart judgments about how you want to use non-linear approaches so that it best reflects the way the patients with severe and severe-to-profound hearing loss can use the signal.
Dynamo (DSESP)
Patients with severe and profound hearing loss respond poorly to too much compression. Dynamo (DSESP) is a proprietary non-linear approach to calculate gain, compression and knee-points for the input/output function. It is different than our voice aligned compression approach, which is a full dynamic range approach used in our other high-end products. DSESP is designed specifically for patients with severe and profound hearing loss. It makes some significant modifications to best reflect what we know about these hearing losses.
For example, we tend to keep the compression ratios low. In our personalization approach which is used to fit the product, you will see a less aggressive use of compression. You will also see that the knee-point we use for compression is significantly higher than we would use in the non-linear approach of other products.
The input/output function in DSESP linear is about 60 to 65 dB SPL. That allows speech through the moderate range to be handled more linearly for patients with severe hearing loss. Some of the soft speech cannot be made fully audible to these patients; if you try to make soft speech fully audible, you end up using more of a traditional dynamic range approach which uses more compression over a broader range. That is the sort of thing to which patients with severe to profound hearing loss do not respond particularly well.
We have found that keeping the input/output function linear through the moderate range gives the signal that punch that patients with severe hearing loss tend to like. If you have tried to fit hearing aids to patients who have worn older power hearing aids and have tried to move into non-linear aids, they will often complain that it sounds muffled or soft or does not have the clarity they are looking for. We believe this is due to the loss of the linear sound quality through the moderate input range. We have created an input/output function in DSESP that we believe better reflects the way patients with severe hearing loss want to get information from the speech signal.
Frequency Lowering
Another important topic when treating severe and profound hearing loss is the role of frequency lowering. We are happy to be introducing our approach to frequency lowering with this new line of Dynamo and Sensei Super Power products. This is the first time that we have used frequency lowering in a product. We have been taking our time to find an approach that makes good sense based on the nature of these hearing losses.
One of the concerns that we have had for several years is the overuse of aggressive frequency lowering to try to make as much of the speech signal as audible as possible. Because of the resolution issues in patients with this amount of hearing loss, you cannot necessarily guarantee that the ear can use the information. We have been working to develop a frequency lowering approach that we believe allows the patient to have access to important parts of the speech signal but is done in a way that preserves the signal so that their auditory system can extract meaningful information.
Who, When and How?
Who uses frequency lowering, when do you turn it on, and how should the system work? This is not a one-size-fits-all solution, and patients are variable in how they respond to frequency lowering. Should it be activated for all fittings from the start, or is it something we employ only when patients are not performing as well as we think they can? That is a broad topic for discussion, but I want to talk about our approach, because that is unique and very important.
It used to be that frequency lowering was used as a solution for cochlear dead zones. A patient with severe high-frequency hearing loss had missing hair cells in that region, so you had to move all that information down to the mid frequencies. That was a simplistic view; as more work was done in the area, some things became clear. First, identifying dead zones in the presence of severe hearing loss becomes very difficult, even with the TENS test.
Second, there is independent evidence that the presence or absence of dead zones does not necessarily predict the usefulness of high-frequency speech information for patients. There are cases of patients who were tested and showed dead zones but then had good high-frequency responses from the hearing aid. Other patients showed they had good hearing in the high-frequency, but for some reason could not use high-frequency information well. The idea that there are either presence or absence of dead zones is an oversimplification.
It is more about the resolution of the auditory system, but I do not think it is easily tested, nor have we come across a clinical test routine that can be used to effectively to determine the integrity of the remaining hearing. Remember, speech must be audible and usable. Just because we can amplify it above threshold does not mean it is usable to the patient. That is something that should always be kept in mind.
Frequency Compression
There are different frequency-lowering approaches used in the marketplace. The most common one is frequency compression. In this approach, the information from the higher frequencies is compressed into the frequency domain of the mid frequencies. At Oticon, we are concerned with this approach for two reasons. First, it abandons the high frequency range. It says that the high frequencies in this person's auditory system are unusable. Additionally, some people use it as merely a feedback control.
Frequency compression should be used when the patient cannot use the high frequencies and when you know that they can handle a highly compressed frequency signal in the mid frequencies. Remember that in many patients with severe hearing loss, there are overall disruptions in the frequency spectrum. To jam a lot of information down into the mid frequencies is concerning to us.
Frequency Composition
The next approach is frequency composition, where information from the high frequencies is selectively chosen and then placed in the mid frequencies where we believe the ear is working better. At the same time, we are keeping the information in the high frequencies. The comparison between frequency composition and frequency compression is a difference in how the high frequencies are being maintained and how you are placing information in the mid frequencies. The high-frequency information is stacked in the mid frequencies because we do not want to disrupt a broad range of the mid frequencies. In other words, we believe that the ear still might be struggling with making good use of information even in the audible mid frequencies, and if we are going to take extra information and place it in the mid frequencies, we want to disrupt only the smallest range of frequencies possible.
In Oticon’s Genie fitting software, we identify a source region in the patient's auditory dynamic range where we believe that we can make moderate signals audible; there are ten choices. Once that source region is selected, we will then identify a higher region that we believe is important to have down in the source region, and then we carefully divide that into two or three different sub-regions and place that in the source region, so as little of the spectrum is impacted as possible.
We believe that frequency composition does a nice job of making high frequencies audible to patients who otherwise may not be able to access them or use that information very well. The movement of the frequencies is much more calculated, and we are careful about how we are treating the speech signal and how we are using that mid-frequency hearing.
Speech Rescue
This frequency lowering approach is what we call Speech Rescue. The source destination is below 4000 hertz, when something is occurring in the high frequencies. Figure 1 shows a spectrogram of the sentence "But if Dr. Simpson's office calls when I'm gone, go ahead and put them thought to my voicemail." Frequency is along the Y axis, low at the bottom to higher as you move upward. I put a line across at 4000 Hz to show the energy above and below this point. The lightness of the color indicates intensity, so the brighter the color, the more intense the signal.
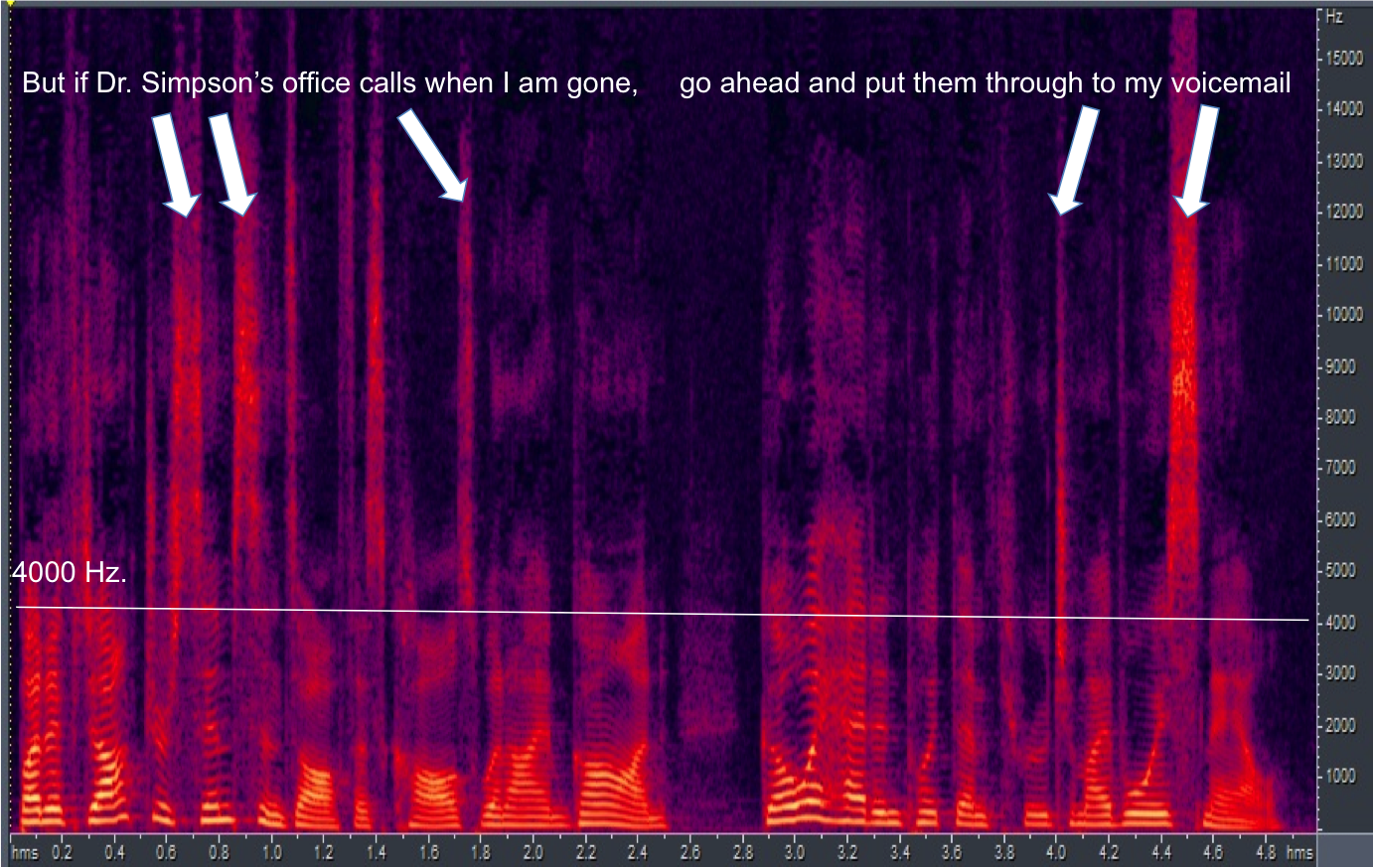
Figure 1. Spectrogram with 4000 Hz cutoff indicated by the white line.
You see significant energy above 4000 Hz. Every time you see this energy above 4000 Hz, there is usually a hole in the spectrum below 4000 Hz. In other words, if you are going to create intense high frequency sounds, typically you are doing it in an unvoiced way. When you do it in an unvoiced way, there is room in the spectrum in the mid frequencies because, at that moment in time, nothing much is happening there. By using a frequency lowering approach that copies this information and replicates it in the mid frequencies, we are not challenging the auditory system too much.
When Speech Rescue is on, information is still maintained in the high frequency because the user might be able to use that information in the high frequencies. The brain can use a lot of information, so there is no problem giving two looks at the speech signal, one in the high frequency and one in the mid frequency. The brain will not have a problem with that.
On a basic level, if you have a high frequency sound like /s/, the first thing we do is rescue it, meaning move it down to the mid frequencies, and then using Speech Guard, which preserves the full detail of the speech waveform, we manage how that information is placed above threshold. Then we can carefully move that frequency down into the auditory dynamic range of the patient, while at the same time, still leaving the /s/ in the high-frequency range for the patient if it is useable there.
How audible we can make the original high frequency signal is going to depend on the audiogram of the patient, and oftentimes when you use frequency lowering it is because this amplified /s/ would not be audible to the patient in most cases. The who and when for frequency lowering is a weighty professional discussion, and we leave that up to hearing care professionals to determine when that makes most sense for patients.
The guidelines from the American Academy of Audiology for when to fit this kind of strategy state that we should abstain from using frequency lowering approaches until we are sure that they cannot get good enough audibility in the high frequencies for speech understanding. Then you might want to consider activating it. As we have discussed, not all frequency lowering approaches are the same. We believe that how we approach frequency lowering sets us apart, and it is done in a way that makes sense based on what we know about severe hearing losses and the physical aspects of speech.
Fitting Considerations
You may notice that some patients with severe or profound hearing loss have difficulty transitioning to new instruments that use a different type of frequency-lowering approach. Some patients might take off right away and do well, while other patients might take a while before they see the benefit. Some patients might struggle because it does sound different. We believe that if you use good technology, you can improve the life of patients by going from an older generation of hearing aids to a new generation of hearing aids, but it might take some time for them to get used to that. We will have a white paper publication on that in the near future.
Bimodal Fittings
A bimodal fitting is where patients wear a cochlear implant on one ear and a hearing aid on the other ear. This is a fascinating discussion because it gets down to how the brain can incorporate information from two sides of the auditory system, when each side is processing in two dramatically different ways. One commonality seems to be that when a patient is wearing solely acoustic amplification with this amount of hearing loss, then the role of the hearing aid is to do all of the work, but when you talk about bimodal fittings, the role of the hearing aid is different, because cochlear implants are more effective at getting good speech information to the brain through a new way of coding.
he role that the hearing aid plays in the presence of an implant is typically secondary to the implant when it comes to speech processing. We have contracted with Carisa Reyes, who is a cochlear implant audiologist at Boys Town, to put together a fitting guideline for bimodal fittings. This is a white paper that is available. If you are interested in getting information on this topic, please contact your Oticon representative.
Conclusion
At Oticon, we take seriously the notion that when you fit hearing aids, you are not changing the person's hearing; you are changing sound. The hearing that the patient has when they start the process is the hearing that they have at the end of the process. Our goal is to try to change sound in a way that the patient, given their hearing anatomy and physiology, can get the most information out of the amplified speech signal as possible. Patients with severe to profound hearing loss have a different nature of hearing impairment.
In order to get the most out of each patient’s individual system, we try to create solutions that reflect a really deep understanding of severe and profound hearing loss. We are quite proud of the solutions in our Dynamo, Sensei, Super Power, and Plus Power products that give you tools that work with this sometimes very challenging clinical population. Although challenging, this group can also be a fulfilling category of patients when you find good solutions for them. I hope that these products and technology strategies have given you the tools to find better solutions.
References
Boothroyd, A. (1993). Profound deafness. In R. Tyler (Ed.), Cochlear implants (pp. 1-34), San Diego, CA: Singular Publishing.
Lamore, P.J., Verweij, C., & Brocaar, M.P. (1990). Residual hearing capacity of severely hearing-impaired subjects. Acta Otolaryngologica Supplement, 469, 7-15.
Souza, P. (2009, January). Severe hearing loss - Recommendations for fitting amplification. AudiologyOnline, Article 893. Retrieved from www.audiologyonline.com
Citation:
Schum, D. (2016, Februrary). Understanding and treating severe and profound hearing loss. AudiologyOnline, Article 16518. Retrieved from https://www.audiologyonline.com.

