
Editor’s Note: This text course is an edited transcript of a live seminar. Download supplemental course materials.
Introduction
Hello, my name is Kelly Austin and I am the Manager of Distance Education for Oticon. Today I want to talk to you about The Oticon Approach and provide an overview of the way we approach the problems of patients with sensorineural hearing loss.
To start, let's take a brief look at our product portfolio. In Figure 1, you can see that our products are divided into levels and segments. The segments are performance, design, power and pediatrics. Each of these segments has different tiers: premium, advanced and essential.
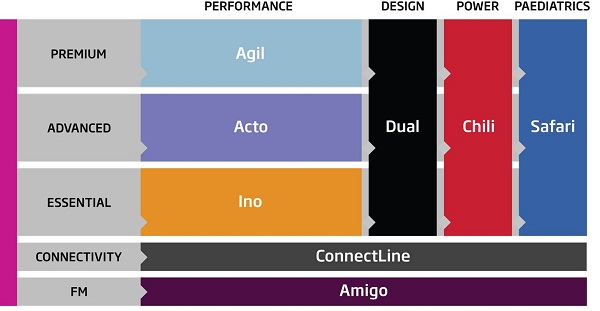
Figure 1. Oticon product portfolio.
In our premium level we have Agil. In our advanced level we have Acto, and in our essential level we have Ino. In the performance segment, across the bottom (Figure 1) you will note that connectivity and FM are available in all of our segments. We have a complete portfolio of products to fit all patients, no matter what their needs.
Over the past year or so, we have been doing some self-discovery in what we stand for as a company, audiologically, and what we feel is important. We wanted to share with you what we are trying to accomplish. For those of you who have been working with Oticon for a while, these things will sound relatively familiar, but for those of you who are new to Oticon we wanted you to know who we are and what we are about as a company, from an audiological standpoint.
One of the things that came out of this process is the realization that we are able to capture what we stand for audiologically in a variety of relatively short statements. These statements form the basis of how we think about hearing loss. We think about the challenges your patients face and how we can go about trying to solve their problems. These four statements are: make optimal use of the capacity the patient has, complex situations are complex, speech understanding is a cognitive process and automatic and effortless hearing where ever and whenever the patient wants to hear.
Make Optimal Use of the Patient's Hearing Capacity
One of our first goals is to make optimal use of the patient's capacity. What we mean by that is that we do not change hearing. Your patient's hearing is your patient's hearing. They show up with a certain amount of hearing capacity. The disorder they are dealing with has changed their hearing in a certain way, and that is what you have to work with; we do not see this as a problem we are fixing. Rather, we see this as making use of their existing hearing capacity. The patient comes with certain hearing abilities that have been altered, and that is our starting point. When we go about creating technology solutions, fitting solutions and counseling-based approaches, they are based on this understanding that we will work with what the patient has to bring us. Importantly, we see this not only as a hearing issue.
One of the other things we will talk about is the cognitive capacity of the patient, or their ability to process information and make use of it. We know that can change with aging, and we have to account for that in the solutions and the way we build things. We are not trying to change the patient; we are trying to assist the patient in using what they have in the best way possible. It fundamentally affects much of what we do. You are not dealing with what they have lost; that is gone. You get to use what they have left and make best use out of it.
By way of an analogy, let's talk about the pirate story. If you are familiar with this story, please forgive me, but it is a favorite of Don Schum’s. Let's say you are a certified state-licensed peg-legologist. Your pirate captain has gone out on the Seven Seas and he has lost the lower half of his leg to a crocodile. Your job is to fit a peg leg. How do you go about fitting a peg leg? Most people would say you would measure the amount of the leg the pirate is missing and cut a piece of wood to match it. Is that the way prosthetic devices are fit today? No, it is much more complex than that.
Today when a prosthetic device is fit, it is not just the distance from the stump to the ground, although that is important and you need it, but it is much more complex. When modern prosthetic devices are fit, they take a very close look at the remaining musculature and bone structure the patient has and even the neural intervention the patient has for some of these neurologically-activated prosthesis. One of the working principles of modern prostheses is that the prosthesis must be integrated into the remaining physiology the patient has. It is not merely strapping a piece of wood to the end of a stump, but it is really integrating this prosthetic device into the remaining physiology of the patient. That is a very effective example when you are thinking about fitting amplification, because that is what you are doing. You are not re-growing the stump. You are not making hearing come back.
It is important to know the thresholds, because that is part of our diagnostic fitting routine, but that is certainly not the end of the job. What you get to work with is not what they lost. What you get to work with is what remains for the patient. What is that remaining structure and function? You know it is going to be disordered because it is sensorineural hearing loss. The physiology has changed, but that is your palate to work with now.
So when you go about the process of fitting amplification we would strongly encourage you to remember that you are dealing with a disordered system that is always going to be disordered. Your job is to manipulate sound so that when it passes through the disordered system it ends up being usable to the patient to whatever degree possible. This approach affects some very fundamental ways in which we go about fitting hearing devices. You are going to be dealing with a disordered system that is always going to be disordered. And your job is to get as much out of that disordered system as possible for the patient.
Oticon Chili: Nonlinear the Right Way
One of the ways we do this is in how we treat severe to profound hearing loss. Historically, Oticon had a reputation for doing one thing, and that was building powerful, high-quality BTEs (behind-the-ear hearing aids) that were good for people with severe to profound hearing loss. That legacy has stayed with our company all these years. We take pride in our ability to provide hearing solutions that are good for people with severe to profound hearing loss. Obviously, we build products for everyone, but it is part of our legacy and part of our heritage and part of the way we think about things.
When we go about making products for severe to profound hearing loss, one of the things we know is that the capabilities of the remaining physiology of the ear with severe to profound hearing loss are very limited, but there is some capability there. The other thing we know is that there is a lot of variability from ear to ear. You can see dramatic differences from one side of the head to the other in terms of how well that part of the peripheral auditory system works.
When we go about addressing severe to profound hearing loss, it is very much focused on the understanding that there are going to be restrictive limits as to how well that disordered system can process sound. You have to do smart things to get sound through that disordered system. That being said, we are very cautious about using compression. Compression logically makes a lot of sense for someone with severe to profound hearing loss, but they have a very restricted dynamic range. They need a lot of gain to make soft to moderate sounds audible, but you cannot make it too loud, because you are dealing with a dynamic range of only about 20 to 30 dB.
The first idea may be to dial in a lot of compression to get everything to fit in there. But the problem with using a lot of compression to get everything to fit in there is that the ear cannot make use of that signal because it is too compressed. Because those ears have the smallest dynamic range with the most hearing, they are also the ears that have the poorest resolution ability. This idea of using nonlinear processing to maximize audibility has to be balanced with what you feel that the ear can get away with in terms of compression and how good the resolution is.
There is a tremendous amount of variability between patient to patient and how you handle that. Our solution around severe to profound hearing loss builds all of that into the way we approach it. This is just one example of understanding this idea of the capacity of what you get to work with and trying to make the most out of the remaining capacity the patient has. We do have to keep in mind that we have to solve the audibility challenges that patients face. We have to use greater amounts of gain for soft and moderate speech inputs in order to provide the benefits of nonlinear processing. However, we also need to preserve the full dynamic properties of the signal, including temporal details and amplitude.
We know that sensorineural hearing loss is usually progressive over time, so when a hearing-impaired individual is fit with amplification, the new sound can be somewhat overwhelming until their system adapts. Adaptation Manager, an Oticon original idea, allows patients to start with amplification set to lower-than-target gain and then gradually increase the gain over time, giving the patient a chance to get used to the sound. This is a good example of not just viewing the patient automatically, but also appreciating their life course and recognizing the need for gradual reintroduction to sound and working with what the patient has.
Complex Situations are Complex
Another major statement is that complex situations are complex. We do not like to play the game where noise is presented as speech-shaped noise or babble like on a recorded audio track. The situations in which your patients find themselves struggling are real, complex situations. Think of a situation where you are talking to someone and there are several other conversations going on in the room. The conversation changes; maybe you are talking to one person and then you change and talk to someone else. You use your hearing the way it was intended to be used. You use it to allow yourself to be immersed in a complex listening situation and get the most out of that.
Our goal is to recognize what situations are like. That is what patients want to be able to do. When we talk about creating technology-based solutions to help patients work well in complex situations, we want to be very honest about those situations and what they are like. Usually they are far more complex than what we pretend from a traditional audiological standpoint. To put a patient in a booth and test word recognition with a background of speech-shaped noise or babble that tells you something diagnostically perhaps, but it does not capture the totality of the experience they are having, and we have to understand that. We also understand that when we look at solutions, we have to model them under the impression of what true communication situations are like, and they are truly complex.
Basically, this is a reality check of hearing aid technology. We sometimes think, "If I just had the right directionality or the right noise reduction or the right this or that, somehow I am going to solve all my patient's problems in noise." It does not happen that way. It is not that simple. Technology, especially directionality and noise reduction, can do some things to help in noisy environments, but it is very dependent on the nature of that noisy environment. Speech in noise is a clinical concept that you test by using a recording from AUDiTEC of Saint Louis. It is not the reality of the world. When your patients go throughout their day, every environment is going to be a little bit different acoustically. There are going to be different sources of noises coming from different directions with different spectral contexts and different dynamic properties. There are going to be different reverberation components in the room. The listening tasks the patient will encounter are going to be different. Sometimes they really care about what they are hearing, and other times they really do not care at all to hear what they are hearing.
The location of the noise may change; the importance of the noise may change. For example, if you are walking through a busy airport, you really do not care what is going on until there is an announcement on the overhead system that is about your flight. Then you tend to pay attention a bit. Every environment is a little bit different. There is no one-size-fits-all magic solution that is going to solve speech and noise for a patient, because it is very much tied to the specifics of that particular environment.
What sort of solutions have we created, and how do we go about creating solutions to meet these goals to be consistent with these principles? If you look at how the profession of audiology has treated sensorineural hearing loss for the past 20 years, the best way to describe it is that we try to maximize clean audibility. When we look at widespread hearing aid technologies that patients with sensorineural hearing loss end up using, the goal is to maximize clean audibility.
We have fitting rationales designed to give comfortable audibility for soft, average and loud sounds. We use directional technology to try to clean up the signal-to-noise ratio whenever possible. We use noise reduction technologies to reduce the response of the hearing aids for situations that seem to be dominated by noise. But it is all in the direction of trying to maximize clean audibility, because as we know, you need to be able to hear the sound. The sound has to be above the patient's threshold and above the background noise level in order for the patient to get any good information from it.
All of our focus has been in this area. But when we look at the technologies we use, such as wide dynamic range compression (WDRC), directionality and noise reduction, they fundamentally have not changed in the last ten years or so. WDRC as a fitting solution became popular back in the 1990's. The rules of fitting a nonlinear hearing aid in terms of the amount of gain at different levels were established throughout the ‘90's. We figured out what those rules should be, and those have not changed too much. In the mid to late ‘90's we started to see adaptive and automatic adaptive directionality show up. At the same time we saw noise reduction strategies show up. For the last ten years those have been the three key technologies that have been used in our field to solve this problem. They have gotten better incrementally. Directionality works more fluidly to meet the patient's needs. We have more channels in WDRC instruments. We have more fine-tuning ability. Some of the fitting rationales have been tweaked one way or another, but our fundamental approach to solving the problem has not really changed in a decade. These principles are extremely important. We use them with every hearing aid we sell.
These are the fundamental technologies that every hearing aid company uses in their hearing aids. But what we are interested in, as a company, is going beyond that. Knowing that we figured out this part, as a field, we understand maximizing clean audibility. We do it as best we can as possibly can, but what more can we do about it? That is the nature of the way we have been approaching signal processing over the last few years. The way that we like to characterize that is to say that what we have been trying to do is provide full information to the patient. Let's take a look at some of our technologies and what make our systems a little more unique.
Directionality
For our directional system, there are two unique aspects. The first is decision making. It is based on the best signal-to-noise ratio, meaning that the signal processing will evaluate all the potential states and will implement the one with the best signal-to-noise ratio. Unlike prediction-based systems, this assures that the best state is always implemented.
We also have split directionality. Most systems switch between omni-directional and directional modes. In situations with moderately-loud input levels, many directional systems will switch to omni-directional in order to avoid the side effects of directionality, which compromises the speech signal. With split directionality, the low-frequency band switches to surround and the upper three frequency bands stay in directional, so the signal-to-noise ratio is improved and the sound quality is preserved. These two approaches show that we understand the complexity of environments and also understand what it takes to make directionality usable and acceptable to patients.
If you look at Figure 2, you see clean speech in the top left panel and you also see some busy room noise in the top right panel. At the bottom there are two panes that both have speech in noise. Which would you prefer to listen to? Which one has the better signal-to-noise ratio? Clearly the one on the left. The decision to switch modes is based primarily on a parallel assessment of the signal to noise ratio provided by each of the available directional modes. The one with the best signal-to-noise ratio is the one that is chosen. It is easy to see this visually, but it is a unique way to process. Many other systems are based on the overall signal level or spectral shape. Many choose directionality when it is not needed or useful, which is not consistent with what patients want.
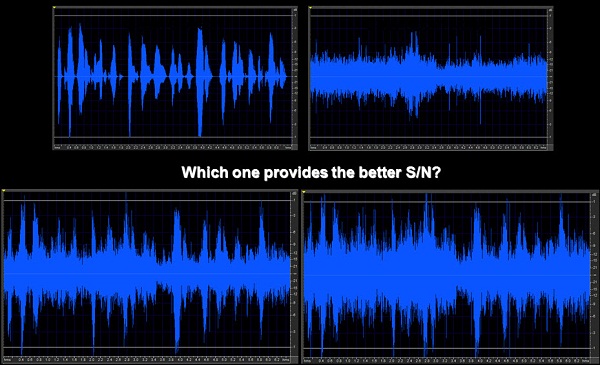
Figure 2. Speech-in-noise samples, with clear speech (top left), noise alone (top right) and speech imbedded in noise at differing signal-to-noise ratios (bottom panels).
In Figure 3 you can see that omni-directional or surround mode is on the top and the full directional is at the bottom. The middle slide is directionality where the low frequencies are in surround and the upper three frequency bands are in directional mode. It improves the signal-to-noise ratio and maintains the good sound quality. Split directionality also allows us to be in directional at lower overall levels and, thus, a greater proportion of the time.

Figure 3. Directionality schemes from omni-directional (top), split directionality (middle), and full-directionality (bottom).
Noise Management
Let's switch gears. We are going to talk a little bit about noise management. We all know what speech looks like. And we know what noise looks like. However, how can we analyze a signal well enough to tell the difference between noise only or speech in the presence of noise?
In our TriState noise management, there are three distinct states to cover the three critical listening situations that people face during the day. There is speech in quiet, speech in noise, and noise only. In those situations where it is unclear if it is noise only or speech in noise, the system first looks to see if speech is present. This is done with synchronicity detection. If the system decides speech is present, then it asks how much noise is present in each channel. Once this analysis is done, then it decides how much it needs to attenuate the noise. As I said, the amount of attenuation is based on the amount of noise present in each channel and whether speech is present or not. If speech is in quiet, then no attenuation is necessary. If there is speech in noise, then some attenuation is necessary, but not too much, as we do not want to compromise the speech signal. Remember, the overall goal is to preserve the speech signal; as they say, you do not throw the baby out with the bath water. Finally, if only noise is present in the signal, then a greater amount of attenuation is applied.
Identities
Another concept that we have in our hearing aids is called Identities. Identities control a variety of different automatic processes in the hearing aid. When you use directionality, noise reduction, and compression systems in your hearing aids, they can operate in a lot of different ways. They can lower and raise thresholds of the activation. They can respond more quickly or they can respond more slowly. There are a lot of things that can control automatic functions in the hearing aids.
If you have software with 50 dials that you have to set to try to figure out a solution for complex listening environments for your patients, that is not really a sensible solution. I suspect you would not like it very much. No one is going to understand how to set those 50 different things independently. So what we do is we capture these Identities: Energetic, Dynamic, Active, Gradual and Calm, which are master controls or meta-controls that control all these functions together. The idea is that these controls are designed to operate in a way that can control the way the hearing aids respond to changing environmental conditions. In other words, if you are in a room where it is quiet and you are listening to one basic source of information, then you do not really need a fancy hearing aid. Anything that improves audibility is going to help you. But if you go to a busy restaurant, ride on a train or any type of changing environment, there are lots of things in the hearing aids that can respond to the changes in the environment. Identities manage how those automatic systems respond to the changes in the environment.
It turns out that patients like the hearing aids to operate in different ways. Some patients like them to not react a lot to changes in the environment because they want the sound to be stable and they do not want to hear the hearing aid working. Other patients however, want to hear their hearing aid reacting quickly. They want to know a new sound source occurs in the room. They want the hearing aid to respond, and some patients want to hear that action. They want to know that something happened. That is a preference issue. Identities are designed to handle changing environmental conditions in a way that tends to match the preferences of the patient. Again, it gets back to this notion that we know that complex situations are complex. There are a lot of things that can go on. You do not know what part of the hearing aid you are going to need at any given time. You do not know if directionality is going to make a difference or noise reduction or a response out of the compression system, but you want to be sure you have some level of control over it.
Speech Understanding is a Cognitive Process
Speech understanding is a cognitive process, and hearing aid technology is a supplement to what the brain can do not a substitute. That is fundamental about how we go about doing signal processing. We understand that the very best signal processer that we have going for us is the patient's brain. The human brain can do a tremendous amount of complex processing of input stimulation and make sense out of it very effectively as long as it has good input. So when we take a look at creating signal processing approaches, our goal is to provide input into the auditory system that we believe is in the best possible form for the brain to make good use out of it. One of those challenges we know is that we have to change the signal before the auditory system is going to screw it up. After all, we do not put the hearing aid after the cochlea. We know something is going to go wrong in the inner ear. We do not know exactly what is going on in any individual, but we have a pretty good guess of some of the types of things that might go wrong. But that varies again from patient to patient.
We know something is going to go wrong in the patient system, and the best we can hope to do is to pre-process this signal in a way that, once that disordered ear takes over, the patient ends up with something that is usable to the brain. You all know that this is not something we can completely solve. Nobody can understand the complete nature of every individual's disorder. But we have pretty good ideas of what we are working with. The goal is to feed the brain what the brain needs. Once the brain gets a hold of it the brain is going to do what the brain is going to do. So we have to feed the brain very good information. When we go about putting together solutions, this notion that listening is something cognitive and happens up at the brain, is fundamental to the way we approach signal processing.
As I said, speech understanding is a cognitive process. It is more than just word recognition. It is the ability to extract meaningful information from the on going conversation. There is a purpose behind speech understanding. People do not listen just for the sake of listening. They do not listen just to hear words. As a matter of fact, you are not listening to me just for the words I am saying; you are listening because it matters what my meaning is. What is my intent? What message am I trying to convey? That is what comprehension or understanding is all about. It is to get meaning and make use of it.
One of the things we know is going on in real time is often other speech. Again, complex situations are complex. And one of the greatest complexities you can put into a listening situation for a hearing-impaired listener is competing speech. That is the most demanding signal you have to work against. If you are in a complex situation, perhaps in a restaurant with a group of friends, sometimes a conversation is with the person next to you, but then it might switch to the person across the table, or it might switch to the waiter. Then when you are not talking to the waiter, perhaps the waiter is talking to someone across the table. So the waiter who used to be the figure is now the competition. Now you are trying to suppress that information. People with normal hearing can navigate this situation without a problem. They can shift between those different sources and decide what they want to listen to, but it does not always happen that way for a person with hearing impairment. They have trouble with that shifting ability. All those things need to be considered when we talk about speech understanding and complex listening situations.
The term we like to use is organize, select and follow. That is what a person with normal hearing does in a complex listening situation. The first thing the brain does for you, and typically below your level of conscious awareness, is to organize the sound sources in your environment. Figure out what is causing all the stimulation to your auditory system and what it gets assigned to. Things are happening in your periphery, but you do not listen in your periphery; all you do is code acoustic information into neural impulses. Those neural impulses then go to the brain and the brain sorts out what these different sources of sound are. Then you select the one you are most interested in, and you listen to it and follow it over time. Remember, speech does not do you any good one syllable at a time. Speech is a signal that only has meaning over time.
Organize, select and follow is a natural process that people use when we go about looking for solutions. That is fundamental to the way we think about it. That is what we are trying to allow our patients to do is to be able to handle the organize, select and follow process to the best possible level, given the restrictions of their hearing impairment. We consider speech comprehension to be a triple-X feature.
Do not get all worried here. This is all still G-rated. What we mean by this is the brain's job is to listen to speech and be able to combine information across frequency, across time, and across ears, hence, the triple X. In other words one particular speech sound means nothing unless you combine it with other things that happen over time in different frequency, regions, and often between different ears when you are trying to resolve and then organize your space. All of that is done at the level of the brain; none of that happens in the periphery. The only thing that happens in the periphery is that a small sound perhaps fires some neurons that run upstairs and then fire up your cortex. Then you start to link those firings in your cortex to meaning.
The reason I make this point is to keep on focusing on the brain. What does it take to give the brain what it needs in order to do this triple-X process across frequency, across time, and across ears? We assert that sensorineural hearing loss is a loss of the ability to organize sound. That should sound a little different to you, because as hearing care professionals we have always been taught about hearing loss. We have been taught that when you talk about your patients to use the term loss. We often talk about the sounds they cannot hear. But we know it is more complex than that.
When patients come in and talk about the difficulties they are having, they do not talk so much about what they do not hear; they actually talk more about hearing too much. For example they might say, “I keep hearing all these sounds; there is so much information coming at me at once.” Are they hearing more sound than the normal hearing person? Well, no, they are probably actually hearing less, but they feel they are hearing so much more due to this inability to organize the sound. They do not know what to do with all that stimulation coming into their system. The normal-hearing person does just fine, because it is coded very cleanly in the periphery. Because of the nature of sensorineural hearing loss and the way sounds are distorted through the periphery, the brain cannot do its organizational job. So when we talk about focusing on signal processing, this is what we are focusing on. It is doing whatever we can to allow the brain to do a better job of organizing what comes up to it.
An example of providing full information would be Spatial Sound. Some of you may have already seen this graphic in Figure 4 of the natural relationship of the level of the ear closer to the signal versus the ear farther from the signal. We know that, due to head-shadow effect in the mid to high frequencies, that sound is naturally louder on one side of the head versus the other. That is information the brain uses to organize sound in the environment. It is part of the organize, select and follow process. You take those two sounds on two nonlinear hearing aids that are not talking to each other wirelessly. You know that the hearing aid farthest from the sound signal is going to turn it up more than the hearing aid that is closer to the signal, because the ear farthest from the signal has a softer input level. So basically WDRC is doing exactly what we would want WDRC to do. If the input is lower, you turn it up.
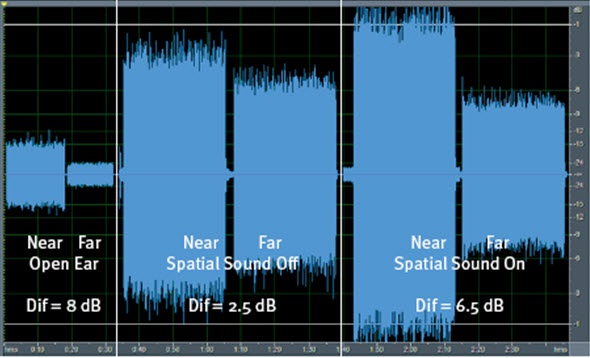
Figure 4. Spatial Sound; differences between sound at the near ear and far ear.
What you see in a set of hearing aids where you do not have that binaural connection is that this natural 8-dB difference between the near ear and the far ear gets reduced to about 2.5 dB. These hearing aids were put on a KEMAR manikin, and they are in about a 2:1 compression ratio. When we turn on the Spatial Sound feature, the wireless connection between the two hearing aids connects to the compression. What you see is that the difference between the near ear and the far ear gets restored up closer to that natural 8-dB difference (Figure 4).
This is what we mean by preserving full information, because none of this is dealing with audibility of the signal. This is a nonlinear hearing aid. That is going to solve the audibility issue. This is going beyond what directionality and noise reduction are able to do. This is what extra information the brain needs in order to organize the sound environment. Part of the organizing process where the sounds are coming from and the level of the information on one side of the head versus the other is one of those sources of information that the brain is looking for. That is one of the things we want to preserve. When we talk about going the extra step of preserving full information beyond just getting good audibility, this is an example.
Historically when we used fast-acting compression hearing aids, it was because we did not want to miss any soft consonants. So if we had a loud vowel followed by a soft consonant, we wanted to be certain the gain readjusted quickly so that the soft consonant was audible. It is a reasonable principle, and we have used it in the field for many years until we started paying attention to what the implications of using it would be. A compression system is a dumb system. Meaning, it does not analyze if sounds are speech or just acoustic energy. So anytime the level drops, whether it is going from a vowel to a soft consonant or a vowel to silence, there is a pause in speech, so the gain is going to be turned up. There is no filter in the system to say, "I am only going to turn it up when there is a soft consonant following a vowel." It turns it up anytime there is a drop in energy.
The extra noisiness of the signal is just background fill, and the soft input level was well below the peeks of speech, because every time that peek goes away you are between the peeks of speech. Then the system turns itself up and the sound becomes noisier. So, yes, you are capturing those soft consonants, but you are also capturing everything else, and it makes it much noisier.
On the flip side, there are some problems with long release times, one being drop outs. Historically, if a loud sound jumps into the environment like a doorbell or a dog barking, with a long release time, you are going to miss everything after that loud sound occurred for a short period of time. Drop out is not good to have because you are missing audibility, and it can make the sound sound like an unstable system.
For years, that has been the compromise of using fast versus slow-acting systems. As a company, we generally prefer to use slow release rather than fast release because we felt the down-side was not as significant. That has all changed with speech guard. The goal is still the same as with all compression systems, which is audibility across the full range of inputs. But because of this dynamic property of speech, we do not want to lose any of the dynamic properties of the speech signal. We want to keep the speech signal in its most natural form. Because we are always thinking about how the brain is going to respond to sound, we do not want to create sound quality problems.
The goal is to keep the signal and gain very stable, not changing on a moment-to-moment basis. Now I know you might say, “Isn't that the whole reason that I use a nonlinear system, because I do want the gain to change on a moment to moment basis?” Remember that the goal of the nonlinear system is to provide audibility across the full range of inputs. The goal is not that the gain has to change for every speech sound. The goal is that you are getting enough speech information into the patient's remaining auditory dynamic range that they can make use out of it. But if you can accomplish that in a better way without causing sound quality problems, that is a better way of doing it.
The goal is to not change the gain if we do not have to. Set the gain to the long-term level of speech you are listening to, and hopefully it stays there for a while, but the sound environment does change. When someone coughs, drops something or slams a door, you want your hearing aids to respond to that. You do not want that sound to come blasting right through or it might end up being too loud. You need to be able to respond to changes in the dynamic environment, but the goal is still to keep the signal as stable as possible.
The way Speech Guard works is to have the signal monitored in different ways, with the goal being to maintain stability. The hearing aid should be driven by the principle voice you are listening to most of the time and does not change. So you do not get that soft fill. You get a long-term parameter in different channels that makes sense based on the patient's audiogram. But if a dog barks or a door slams, or if the talker drops the level of their speech significantly, you want a very fast reaction to the system to compensate and maintain audibility, but then get stable again very quickly.
This actually has principles of both slow and fast-acting compression. It has the principle of slow-acting compression in that you do not want it to change gain much at all. But it has the principle of fast-acting compression so that if the sound environment truly changes, you have a very fast reaction to that change. It cannot be classified as a slow-acting system or as a fast-acting system, because it has elements of both of them. It is that monitoring of the two different systems in different ways that can allow this to happen.
Another way to look at Speech Guard is in a waveform. You have all seen wave forms before and you know that speech is a relatively complicated wave form. One thing that is important is the beginning and the ends of speech sounds. Our cognitive sensory system is very in tune to edges. For example, you have all done visual illusions where you look at black and white squares and you see the gray dots in between. In the visual system they are called edge effects. Your visual system is very in tune to the edges of the figures because it usually carries a lot of information.
Take a look at the two signs in Figure 5 and compare them. Which one is easier to read? When you are driving down the highway at 70 miles an hour at night in traffic, it is this edge effect that helps you to read the second sign more easily. There was actually a lot of research behind the fonts used on road signs to determine which are most effective and which are easier to read. A similar sort of thing happens in the auditory system in that the auditory system seems to be very focused on the beginnings and the ends of sound, because that defines the event. This is the sort of information that the brain is looking for. Then it becomes very important that we are clear about how the speech signal is sent up from the periphery, because you want that crisp encoding that sounds started and stopped at certain periods of time.
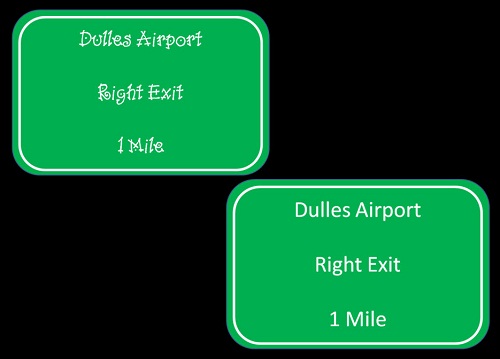
Figure 5.Comparison of two different fonts on road signs, demonstrating the edge effect.
In these wave forms (Figure 6) the first wave, is a signal before it is processed by a hearing aid. The second wave form is the same signal passed through a fast-acting system. The last one is the same signal passed through an aid with Speech Guard. One of the things you will notice is that the contrast of the peaks and valleys of the fast-acting system are not as clear and crisp as they are with Speech Guard. The difference of when it is supposed to be silent compared to bursts of energy is coded so much better with speech guard than it is with the fast-acting system. I know that sounds like a real detail, but when we talk about going beyond WDRC and giving the brain what it needs, that is the sort thing that we are talking about. It is seeing what we can do better, to more precisely code what we are sending up to the brain to make and maintain clear contrasts. Both of these passages are audible to the patient, but it is the precision of maintaining all the details of the speech waveform that makes it different.
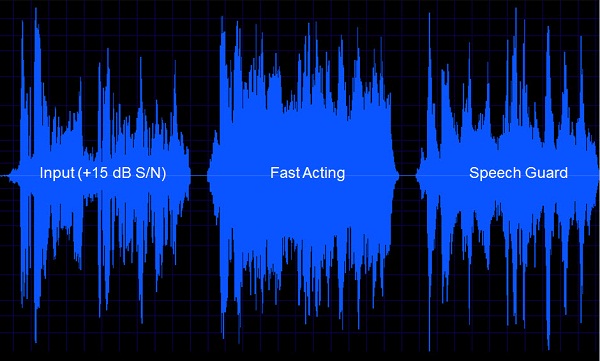
Figure 6. Speech waveforms of original input (left panel), input processed with fast-acting compression (middle panel), and input processed with Speech Guard.
This is a very good example of feeding the brain what it needs in terms of what we can do with technology. We are attempting to maintain those contrasts very cleanly, because the issue is that patients have trouble organizing sound. We want to keep feeding the brain the very best information they need to be able to do that original task.
We did a study comparing our Epoq to Agil. We used 35 experienced Epoq users with different styles. They the users were fit with Agil for four weeks instead of their Epoq. The devices shared Spatial Sound, Bandwidth Noise Reduction, and Voice Aligned Compression. Adaptive speech-in-noise testing was completed. The main difference was that Speech Guard is present in Agil and not in Epoq.
You can see that there is a 1.4 dB improved speech reception threshold of the Agil over the Epoq (Figure 7). That equates to about a 15 to 20 percent improvement, which is statistically significant. It is a huge difference in their ability to hear.
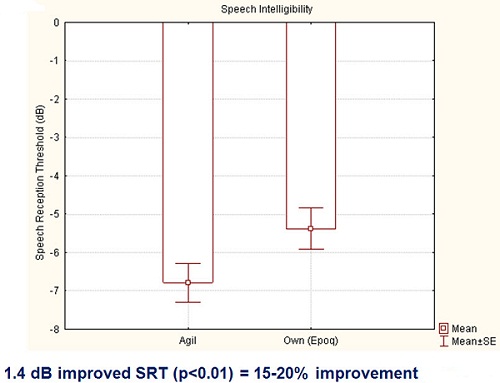
Figure 7. Speech intelligibility comparisons between Oticon Agil and Oticon Epoq hearing aids.
Bringing it all Together
This slide talks about all the things that are happening in the different Identities (Figure 8) and how things could change quickly or slowly, so we are going to do a quick example here. We are going to start out with the loudness in an event that happens over time. We start out with ambient room noise, and then after a period of time, someone starts to talk. So the person is talking, and then eventually the air conditioner is going to start, and then a dog is going to bark, and then the door is going to open.
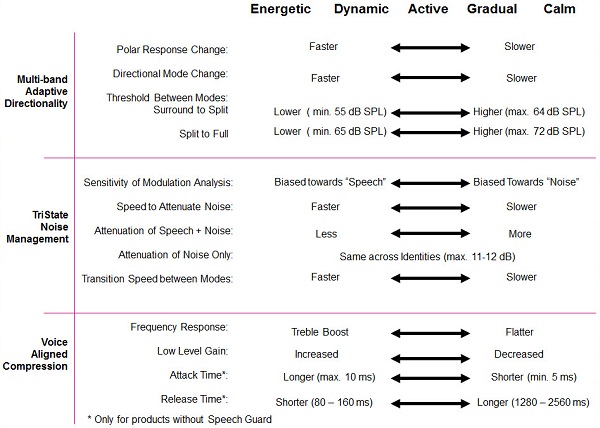
Figure 8. Oticon features in various environmental Identities.
Let's look at this a little more closely (Figure 9). If we look at the signal-to-noise ratio, obviously in the ambient room there is no speech. So, there is no signal-to-noise ratio to speak of. Then the talker begins, so the signal-to-noise ratio is actually pretty good, because the noise in the room is very low. The air conditioner starts, and that changes the scene a bit there. The signal-to-noise ratio comes down a bit. The dog barks, and it takes a quick nosedive and recovers. Then the door opens and the signal-to-noise ratio goes down even more, because there is a lot more noise.
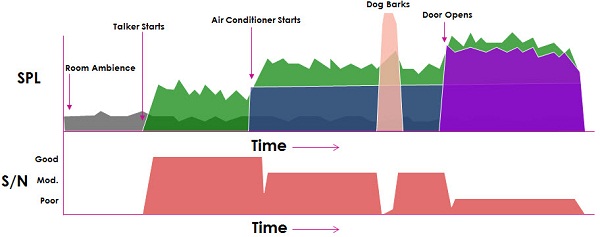
Figure 9. Signal-to-noise ratio changes as sounds in the environment occur over time.
Now let's look at how it compares when we look at Speech Guard, multi-band adaptive directionality and TriState noise management (Figure 10). In room with ambient noise, speech guard the level is pretty stable when Speech Guard is activated. You have full gain. There is no dominant noise source, so there is no attenuation necessary. When someone starts to talk, that moderate level is stable, and then you have that moderate gain and stable gain level which we want in Speech Guard. For directionality, there is no dominant noise source, so it still stays in Surround Sound. Then in TriState noise management, there is a moderate level and good signal-to-noise ratio. Again, there is no need for attenuation.
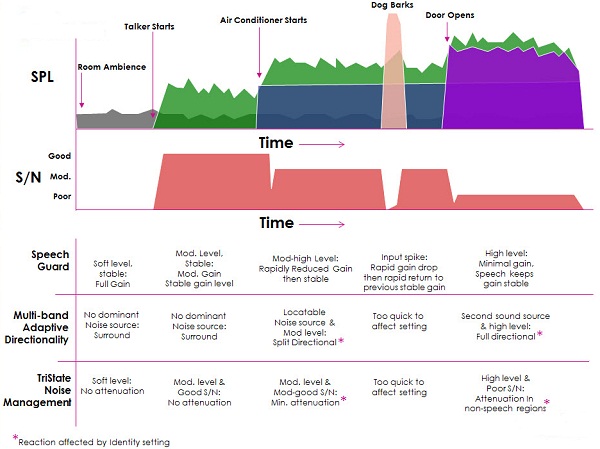
Figure 10. Signal-to-noise ratios over time with application of Speech Guard, multi-band adaptive directionality and TriState noise management.
However, then we bring in the air conditioner and things start to change a bit. The moderately-high level of noise rapidly reduced the gain, but then it became a new stable gain level. The noise source was locatable, and it was a moderate level, so it went to split directionality. Then because there is a moderate noise level and moderate to good signal-to-noise ratio, there is minimal attenuation. You can see in Figure 10 that little spike where the dog barks, and the inputs spike and the gain drops drastically, but then it returns to its previous gain level. That kind of input is too quick for directionality and noise management to react.
Finally, when someone opens the door and the noise level goes up a bit, there is a high level and minimal gain, so Speech Guard keeps the gain stable. The second source makes it high level, so it goes into full directionality and then noise management; there is a very poor signal-to-noise ratio. So there is attenuation in the non-speech regions. This shows you how all those things are working together to try and create the best solution in a changing and complex listening environment.
Automatic and Effortless Hearing
One final statement is that we are trying to achieve automatic and effortless hearing whenever and where ever the patient wants to hear, because this is what a person with normal hearing has access to. They can go anywhere they want and can hear without having to think about it. It is not something to which they need to put in extra effort. They do not have to analyze the situation. That is what we want our patients to be able to do- not to have to work at hearing, not to have to be afraid to go to certain situations, not to withdraw from situations, not to avoid situations because they know it is going to be difficult, but to experience the world, operate in the auditory world without any restrictions on them at all. We know this is a lofty goal. We understand that. We will never reach it in totality, because of the nature of sensorineural hearing loss. But the goal is to allow that sort of access to hearing-impaired patients. It is about creating solutions so the patient has that unrestricted freedom to move throughout the auditory world.
The effortless aspect is a very big part of it. One of the things we have become more and more aware of over the past several years is how much work hearing impairment is. You all know that it is. Your patients come in and tell you that all the time. But we have been very interested in understanding that statement better. We want to know if it is just the hearing loss and not being able to understand words or is there something more to this effort in listening. For example, if you have a patient with word recognition scores in quiet of 100 percent, many times we assume they are doing just fine. But do we really know that? In order for them to achieve that 100 percent, did they have to work twice as hard as a normal-hearing individual in order to be at that level?
Connectivity
One final area I want to discuss is connectivity. We have put heavy emphasis on the role of connectivity in the life of older patients to allow them the contact with people and activities that have always meant so much to them. We know how important it is for them to maintain those connections as they get older. We want them to be able to have those connections as often as possible and where ever they need to have those connections. This is our entire ConnectLine family (Figure 11). We initially introduced our Streamer back in 2007. That was basically for volume control and program changes. We also could allow them to use mobile phones with it and listen to MP3 music. That was fantastic and revolutionary. We were the first company to have this type of technology, and it really took off.

Figure 11. Oticon ConnectLine family.
Then in 2009 we added the ConnectLine system. That included the phone adapter for landline use and the TV adapter for television viewing. This opened up many different opportunities for the hearing-impaired listener, not only for our elderly, but some of our severe-to-profound folks. They especially love having the streamer for telephone use.
Finally, in 2011, we added the ConnectLine Microphone for one-on-one communication in those more challenging signal-to-noise ratios. That, again, was very successful because it helped many people that were still having difficulty. Even with the best hearing aids, sometimes people need a little bit more help. The Streamer is the gateway device that connects all of these devices, providing an integrated solution that is very intuitive and easy to use. It is just the touch of a button to change between different devices, and it is very simple for a patient to learn how to use it.
These statements that we discussed today are designed to capture how we go about putting together solutions. I hope it feels a little bit different to you, especially to those of you who are new to Oticon. This terminology is a bit different from the typical way of describing hearing impairment and the role of technology, but it is important to us and the way in which we do things. Thank you for your time.
Cite this content as:
Austin, K.A. (2013, March). The Oticon approach. AudiologyOnline, Article #11644. Retrieved from https://www.audiologyonline.com/

