
Learning Outcomes
After reading this article, professionals will be able to:
- Describe the differences between single stream processing used in traditional hearing aids and the new split stream processing used in Signia AX.
- Summarize the acoustic changes that split stream processing has on the speech and noise at the hearing aid output at various input conditions.
- Identify potential listener benefits of split stream processing.
Introduction
Hearing aid technologies, for decades, have relied on adaptive directional microphones (ADIR) and digital noise reduction (DNR) algorithms to improve speech understanding and/or listening comfort for wearers. It is well-known that directional technology improves speech recognition performance in noise compared to omnidirectional microphones, while DNR algorithms typically improve listening comfort and noise tolerance with limited improvement in speech intelligibility noted in some studies (see Ricketts et al., 2019 for a review).
An assumption used by many modulation-based DNR algorithms is that speech and noise signals occupy different spectral regions and that they have different modulation characteristics. This difference allows the DNR algorithms to reduce gain in channels dominated by noise while retaining gain in the channels dominated by speech. If speech and noise are spectrally distinct, a decrease in overall output level and an overall SNR improvement may be realized. For example, steady-state noise from a household appliance such as a refrigerator or air conditioner is spectrally distinct from the human voice; thus DNR algorithms can be quite effective at reducing this type of diffuse background noise with little impact on gain for speech. In contrast, when speech and noise occupy the same frequencies, the overall output level in each channel is reduced, but the overall signal-to-noise ratio (SNR) within that same channel may not be improved. When and how much gain reduction occurs in a DNR algorithm is affected by the input level, the estimated input SNR, and the modulation characteristics of the input signal. Table 1 includes definitions of signal processing terms as they are used here.
Input level: Sound pressure level measured at the listener position without hearing aid processing. |
Input SNR: Ratio of speech and noise levels measured at the listener position without hearing aid processing. |
Output level: Sound pressure level measured at the hearing aid output after hearing aid processing. |
Output SNR: Ratio of speech and noise levels measured at the hearing aid output after hearing aid processing. |
Table 1. Definitions of common signal processing terms.
Directional technology also has limitations. The effectiveness of directional microphones, including adaptive directional microphones (ADIRs), is predicated on the spatial separation of speech from other extraneous noises. In the optimal listening condition, when the talker(s) of interest is spatially separated from noise, adaptive directional microphones reduce the overall output level while improving the output signal-to-noise ratio. The polar pattern of the microphone can vary adaptively depending on the nature, intensity, and azimuth of speech and noise.
In a traditional hearing aid, the input signal, including speech and background noise, is first processed by the microphone system before it is processed by the compressor and various noise reduction algorithms. Consequently, the same DNR and compression settings will be applied to both the speech and noise present in the post-microphone signal. This limits the improvement of the SNR at the hearing aid output. Signia recently introduced split processing, called Augmented Focus, in its Augmented Xperience (AX) platform to separately process sounds arriving from different directions to enhance the contrast between speech and background noise (Best et al., 2021). Specifically, the input signal is split into two separate signal streams (Figure 1). One stream consists of sounds originating from the front, while the other stream contains sounds coming from the back. This can be achieved by using bilateral dual microphones to create two different polar patterns for the front and the back sources. Each stream is analyzed and processed using independent compression and noise reduction parameters. The target sound may be provided more linear gain and less gain reduction by the DNR to further enhance its salience, while background noise may be processed with more compression and more gain reduction. After the two streams have been processed independently, they are mixed intelligently based on a soundscape analysis to form the final output.
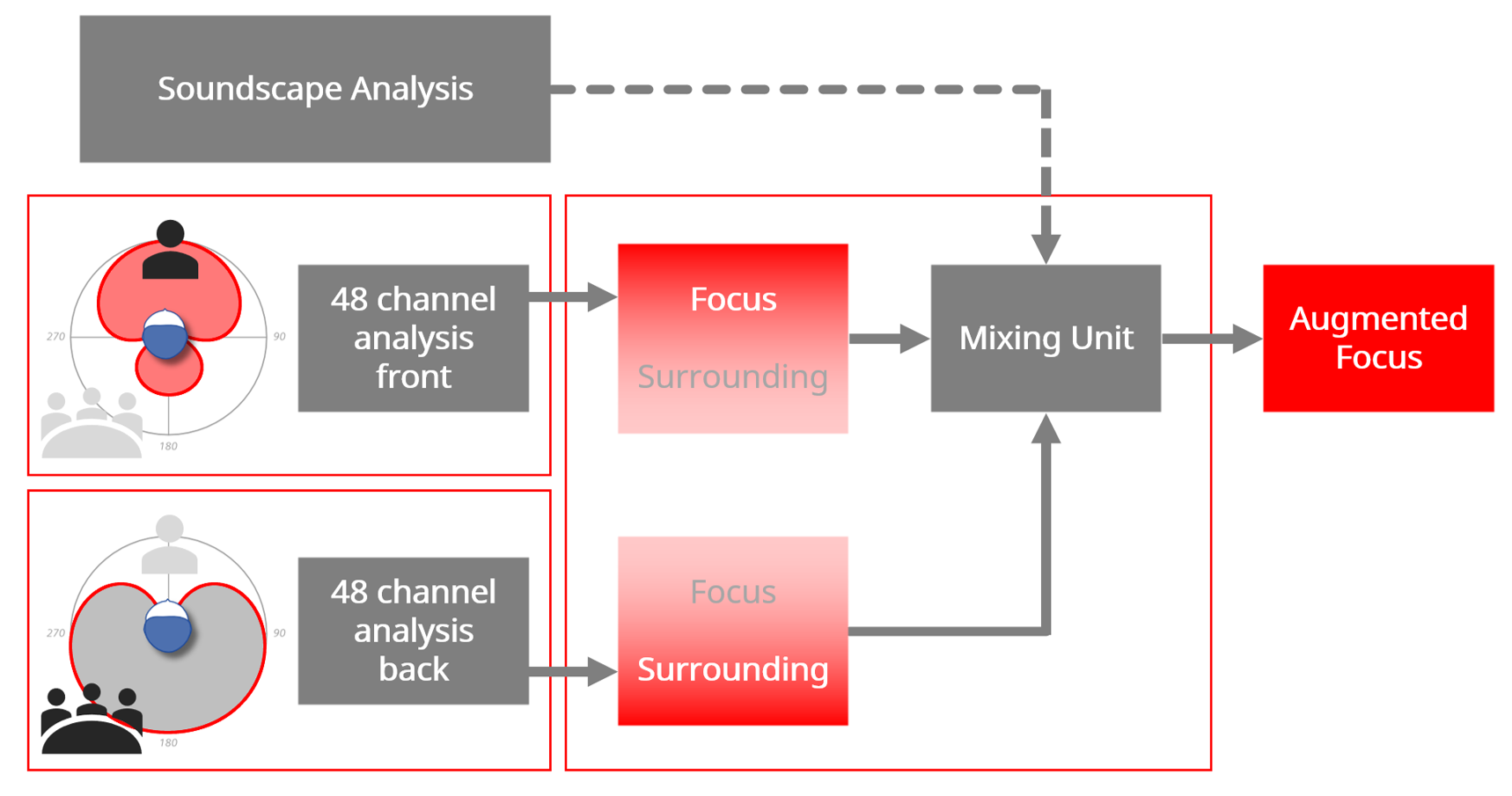
Figure 1. Outline of the relevant processing units in Augmented Focus: Analysis stage; Processing Unit; Mixing Unit. In this example, the Focus area is to the front. Note that Focus could be in any direction.
As a pre-condition to study the behavioral benefits of split processing, we performed acoustic measurements of this feature and compared those measures to the effect of other common processing algorithms, including digital noise reduction and adaptive directionality used in Signia hearing aids. Our objective was to estimate how each feature contributes to the overall changes in the acoustic output over a range of input and SNR levels.
Method
All data in this study were collected via electroacoustic measurements on the Knowles Electronics Manikin for Acoustic Research (KEMAR) inside an audiometric test booth. The International Speech Test Signal (ISTS) (Holube et al., 2010) and the International Female Noise (IFnoise, EHIMA, 2016), an unmodulated continuous noise that has the same long-term average spectrum as the ISTS, were used as the test signals.
Hearing Aids
Measurements were conducted using a full-feature version of the Signia AX, and a second Signia product with the same processing, except that it did not have split processing. The hearing aids used in this study were programmed based on the NAL-NL2 gain prescription for the N3 standard audiogram (Bisgaard et al., 2010). The DNR and directionality were set at the Connexx software defaults for this mild sloping to moderate audiogram. The hearing aid (HA) conditions included single-stream processing in the omnidirectional microphone mode without DNR, adaptive directional microphone mode with DNR, and split processing with adaptive directionality and DNR, as summarized in Table 2.
| Processing Condition | Description |
| UA | Unaided |
| OMNI | Omnidirectional microphone, single-stream processing |
| ADIR + DNR | Adaptive directional microphone + DNR, single stream processing |
| SP | ADIR + DNR + Split-band processing |
Table 2. Processing conditions used in the measurements.
Acoustic Measures
The acoustic changes at the hearing aid output were quantified using the phase inversion technique (Hagerman & Olofson, 2004). The phase inversion method is an acoustic measurement technique that provides access to the speech and noise signals separately at the hearing aid output. This method is based on making two recordings where the phase of one signal is inverted between the measurements. Summing and subtracting the two recordings together results in separation of speech and noise at the output of the hearing aid (Figure 2).
After isolating the processed speech and noise signals, long-term RMS levels of the speech and noise were calculated in each 1/3-octave band from 160 Hz to 8 kHz to obtain the SNR by comparing the log-ratio of the speech to noise. A single SNR index was obtained using a metric proposed by Wu et al. (2013), where the narrowband SNRs were averaged, weighted by the band importance function of the average speech specified by ANSI S3.5-1997 (R2007).
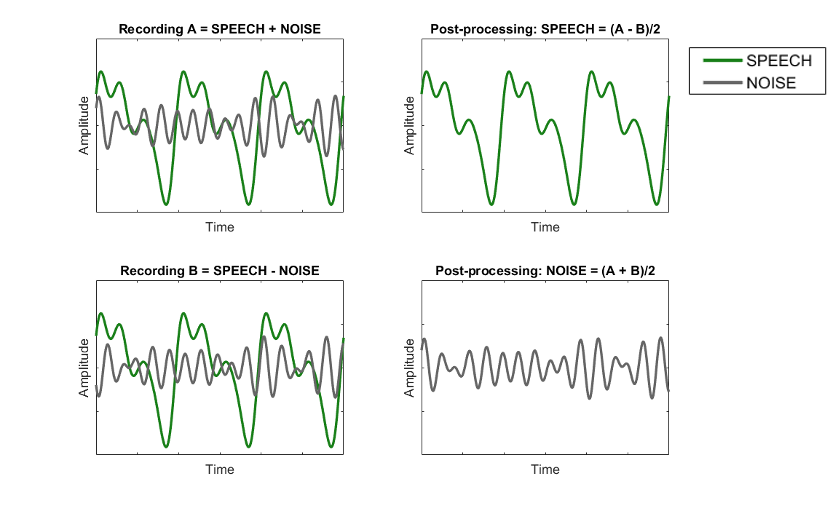
Figure 2. Principle of the inversion technique to separate two signals presented simultaneously. The phase of the noise is inverted in recording B (vs A). Subtraction of the recordings yields speech, while summation yields noise at the hearing aid output.
Recording Setup and Conditions
The study hearing aids were coupled to both ears of the KEMAR with fully occluding silicone ear inserts to minimize the effect of any direct sounds entering the ear canal and confounding the aided measurements. Speech was presented from 0° at 50, 65, and 80 dB SPL. The background noise was presented from 180° at -10, -5, 0, +5, and +10 dB SNR. The most adverse SNR is -10, while the most favorable is +10. Figure 3 shows the basic test arrangement. Only recordings from the right ear were analyzed.
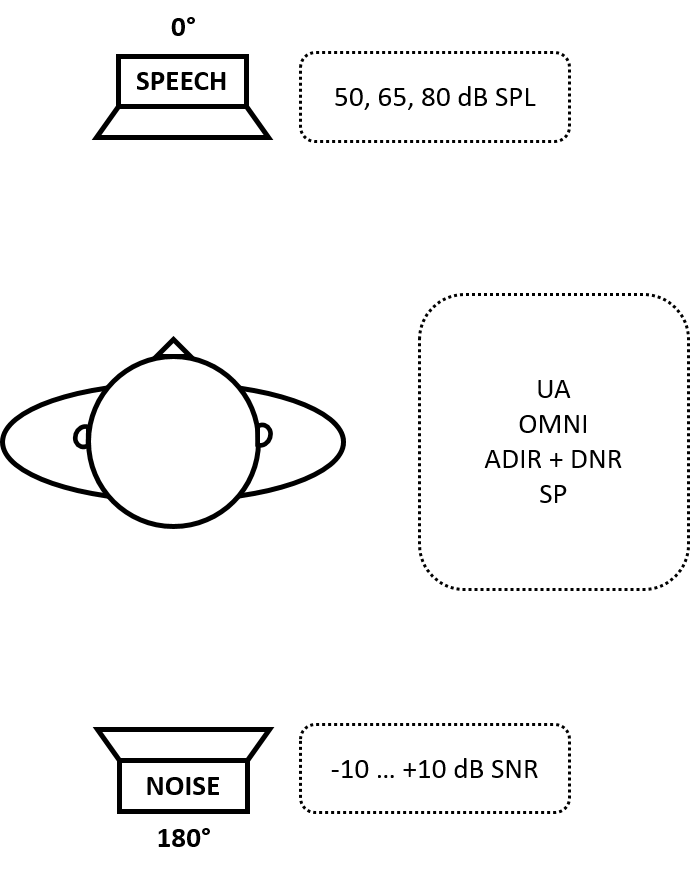
Figure 3. Stimuli and hearing aid processing conditions during the measurements.
Results
Using the arrangement shown in Figure 3, total output, speech output, noise output and SNR output were measured at three input levels (50, 65 and 80 dB SPL). A measurement was also conducted of the unaided condition. Each of these measurements was conducted for each of the hearing aid conditions described in Table 2. A description of each measurement conducted is provided in this section.
Total Output Level
The total output (Figure 4) includes the combined speech and noise signals after amplification. The total output level reflects the overall aided intensity and does not inform us about aided speech audibility for a wearer. This is because the total output level may be driven primarily by speech, by noise, or by both depending on their relative dominance at the hearing aid output.
The Effect of Amplification
Compared to the unaided condition (UA), the effects of wide dynamic range compression are observed in the OMNI condition, as increases in the input yield lesser relative increases in output. No increase in total output level is observed at the highest input condition (80 dB SPL speech at -10 dB SNR; i.e., input noise at 90 dB SPL) due to no gain provided for loudest sounds.
The Effect of Adaptive Directional Microphone and Noise Reduction
ADIR+DNR reduces the total output level compared to OMNI at soft (50 dB SPL) and average (65 dB SPL) levels, and when the input SNRs are poor. At the 80 dB SPL input, the total output with ADIR+DNR is similar across SNRs; the later analysis shows that despite little effect on total output, the ADIR+DNR nevertheless changes the speech and noise levels.
The Effect of Split Processing
Split processing (SP) has similar output levels across all input SNR levels, unlike the single-stream processing, which shows a wider range of output levels when input SNR varied at low and medium input levels. This suggests that SP maintains a constant overall loudness regardless of SNR. In the subsequent analysis, where we analyze the speech and noise levels independently, we will see how speech and noise separately were affected by the split processing.
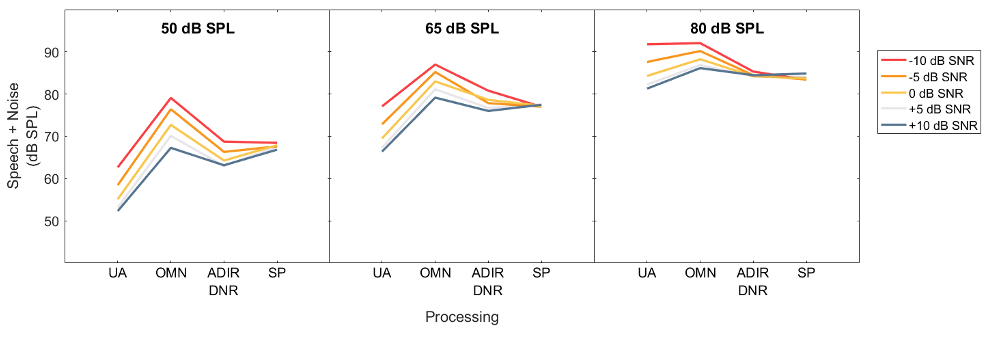
Figure 4. The total output level (speech + noise) measured at the hearing aid output.
Contributions of Speech and Noise
The total output level reported previously does not reveal the relative contributions of speech and/or noise to the overall output. Thus, we measured each separately (Figure 5).
The Effect of Amplification
As expected, the unaided speech level remains constant while the noise level changes according to the intended input SNR. In the OMNI condition, the output speech level is higher at higher speech input levels. On the other hand, the speech level decreases as the SNR becomes more adverse due to lower gain provided by the compressor when the overall input level is higher (driven by louder noise). The range of output noise level change is smaller at the higher input levels because of the compression used.
The Effect of Adaptive Directional Microphone and Noise Reduction
Compared to OMNI, ADIR+DNR reduces the speech level when the input level is low and SNRs are favorable. At higher input noise conditions, the speech level increases. The noise level is reduced in all input conditions. At the 65 dB SPL level, the output noise level is lower at -5 dB SNR input than at 0 dB SNR input demonstrating the activation threshold for advanced processing at around 70 dB SPL input noise level.
The Effect of Split Processing
Split processing results in similar or higher speech levels than single-stream processing (i.e., ADIR+DNR) across all input levels and input SNRs. This suggests that split processing maintains the same audibility for speech without the deleterious effects (on speech). Other than at the 50 dB SPL input at a SNR ≥ 0 dB, SP also yields the lowest noise level. This is because in the dual-stream system, gain reduction is applied only to noise and not to speech.
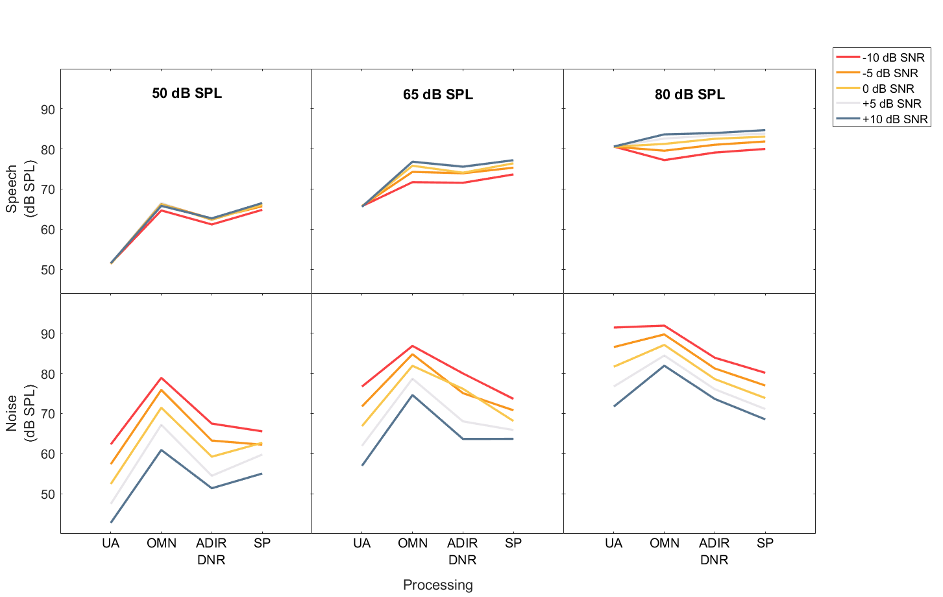
Figure 5. Speech (top) and noise (bottom) levels measured at the hearing aid output.
Output Signal-to-Noise Ratio
Using the extracted noise and speech outputs we can derive the speech-weighted SNR at the hearing aid output (Figure 6).
The Effect of Amplification
Compared to UA, the OMNI results in a poorer SNR than the unaided condition (average of 3.2 dB reduction). This is due to the effect of WDRC and the advantage of the pinna shadow in the unaided mode over the OMNI condition (due to the microphone location of the RIC product).
The Effect of Adaptive Directional Microphone and Noise Reduction
Compared to the unaided, ADIR+DNR improves the output SNR on average by 3.8 dB. The smaller improvement at the lower input levels reflects the activation thresholds. As expected, the combination of ADIR+DNR is more prominent for higher input levels. For example, note in Figure 6, the steep slope between the omni and ADIR + DNR conditions for both the 65 dB and 85 dB SPL inputs. This reflects how automatic directional technology improves the SNR for higher input levels.
The Effect of Split Processing
Split processing improves the output SNR over traditional single-stream processing across all input levels and SNR conditions. The improvement in SNR is achieved while providing a consistent output level across all input noise levels. As shown earlier, the overall output level with SP is even lower than the unaided input at high levels (90 dB SPL input noise). The output SNR with split processing is on average 7.9 dB better than unaided, and 4.2 dB better than ADIR+DNR (i.e., single-stream processing with advanced features). The greatest improvement (re: ADIR+DNR) is seen at the most adverse input SNR condition (-10 dB SNR) at 50 and 65 dB SPL levels. Of note is the improvement in output SNR with split processing for 50 dB SPL (soft) and 65 dB SPL (average) inputs for the most adverse conditions. The steeply sloping line for the -5 and -10 dB SNR conditions show a remarkable improvement when SP is added to the processing scheme. This suggests that when the level of speech is soft or average, and the SNR is adverse, split processing provides upwards of 7 dB of SNR improvement over ADIR+DNR processing alone.
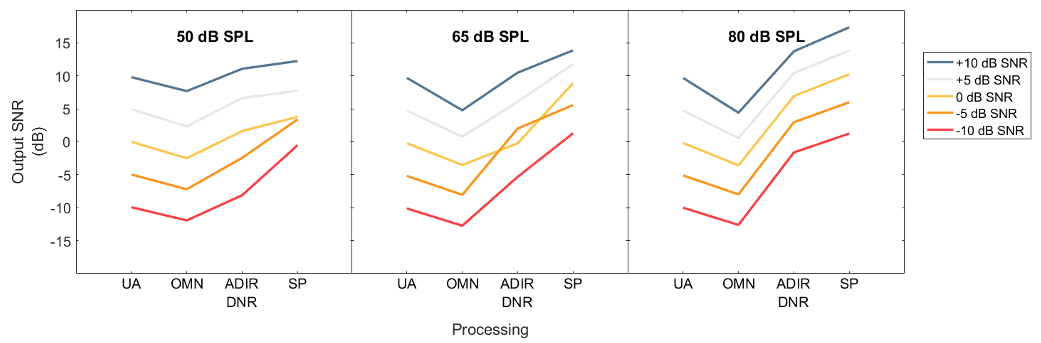
Figure 6. The output SNR across all processing conditions.
Clinical Implications
Even though most individuals do not find themselves in listening situations where the signal-to-noise ratio is unfavorable, say 0 to -10 dB SNR, on a daily basis, these types of highly adverse conditions are believed to be among the most critical places where people communicate. After all, social situations, celebratory events, and other remarkable occasions often occur in boisterous places with unfavorable SNRs. As hearing care professionals know, these types of situations with unfavorable SNRs can be challenging for many hearing aid wearers. Listening with hearing aids in these environments can lead to frustration, annoyance, and dissatisfaction with the hearing aids.
It is also well-established that there is considerable individual variability in performance in these adverse listening conditions, even among hearing aid wearers. Although this individual variability in performance can be assessed in the clinic with tests such as the Quick Speech in Noise (SIN) test (Fitzgerald, 2019), nearly 90% of hearing aid wearers are seeking better performance in noise from their hearing aids (Manchaiah et al., 2021).
When wearers want to communicate in adverse listening conditions, they often demand both better listening comfort and improved speech intelligibility from hearing aids. As stated in the introduction, over the past two decades wearers have relied on a combination of adaptive directional microphones and digital noise reduction algorithms to improve speech understanding and/or listening comfort in these situations. Results of this analysis indicate these features improve the SNR as expected in adverse conditions at a range of input levels.
In addition to the effectiveness of ADIR and DNR, this analysis demonstrates Augmented Focus split processing, a proprietary feature in the Signia AX, improves the output SNR another 2 to 7 dB in the most adverse listening conditions (0, -5 and -10 dB SNR) over and above ADIR and DNR. Although these SNR improvements do not necessarily equate to individual improvements in listening comfort or speech intelligibility, these results suggest wearers of AX split processing, when properly fitted, are more likely to experience better performance in a wide range of adverse listening conditions compared to hearing aids without split processing.
Conclusions
The electroacoustic measurements presented in this study demonstrate how advanced noise reduction strategies influence the speech and noise levels at the hearing aid output. The acoustic improvement in SNR offered by split processing observed in these measurements was validated in separate behavioral studies. The acoustic differences were reflected in improved speech-in-noise performance as shown in these studies. Jensen et al. (2021) measured speech reception thresholds (SRT80) in a simulated restaurant scenario where speech originated from the front in the presence of soft ambient sound, and intermittent laughter from the back hemisphere. The reported benefit with split processing over single-stream processing was 3.9 dB. In another study, Kuk et al. (2022) reported that SP improved the aided noise tolerance by 2.9 dB compared to single-stream directional processing. The magnitude of our measured acoustic changes with Signia AX with Augmented Focus, therefore, is consistent with the results of behavioral studies.
References
American National Standards Institute (ANSI). (1997). American national standard: methods for the calculation of the speech intelligibility index (ANSI S3.5-1997 (R2007)). American National Standards Institute.
Best, S., Serman, M., Taylor, B., & Hoydal, E. 2021. Augmented Focus. Signia Backgrounder. Retrieved from www.signia-library.com
Bisgaard, N., Vlaming, M., & Dahlquist, M. 2010. Standard audiograms for the IEC 60118-15 measurement procedure. Trends in Amplification, 14(2), 113–120.
European Hearing Instrument Manufacturers Association (EHIMA). (2016). Description and terms of use of the IFFM and IFnoise signals. EHIMA, European Hearing Instrument Manufacturers Association AISBL.
Fitzgerald, M. (2019). Guidelines for replacing word recognition in quiet with speech-in-noise testing in the routine audiologic test battery. [Conference presentation]. AudiologyNow Conference, Columbus, OH.
Hagerman, B. & Olofsson, Å. (2004). A method to measure the effect of noise reduction algorithms using simultaneous speech and noise. Acta Acustica, 90(2), 356–361.
Holube, I., Fredelake, S., Vlaming, M., & Kollmeier, B. 2010. Development and analysis of an international speech test signal (ISTS). International Journal of Audiology, 49, 891–903.
Jensen, N.S., Hoydal, E.H., Branda, E., & Weber, J. (2021). Augmenting speech recognition with a new split-processing paradigm. Hearing Review, 28(6), 24-27.
Kuk, F., Slugocki, C., Davis-Ruperto, N., & Korhonen, P. (2022). Measuring the effect of adaptive directionality and split processing on noise acceptance at multiple input levels. International Journal of Audiology, 11, 1-9.
Manchaiah, V., Picou, E. M., Bailey, A., & Rodrigo, H. (2021). Consumer ratings of the most desirable hearing aid attributes. Journal of the American Academy of Audiology, 32(8), 537–546.
Ricketts, T., Bentler, R. A., & Mueller, H. G. (2019). Essentials of modern hearing aids: Selection, fitting, and verification. Plural Publishing.
Wu, Y-H.. & Stangl, E. (2013). The effect of hearing aid signal-processing schemes on acceptable noise levels: Perception and prediction. Ear and Hearing, 34(3), 333-341.
Citation
Korhonen, P., Slugocki, C., & Taylor, B. (2022). Study reveals Signia split processing significantly improves the signal-to-noise ratio. AudiologyOnline, Article 28224. Available at www.audiologyonline.com



