Learning Objectives
- Participants will be able to identify the key differences between ultrasonic and conventional transmission of audio.
- Participants will be able to explain how these differences may result in superior performance for the ultrasonic transmission for at-home television viewing.
- Participants will be able to describe a new product category of devices for patients with hearing loss, called directed audio solutions.
Abstract
Objective: To assess whether the HyperSound® Audio System (HSS), a novel audio system using ultrasound technology, improves speech understanding compared to a conventional acoustic speaker in participants with mild to severe hearing loss.
Study Design: Single-blinded, randomized crossover study.
Setting: Tertiary referral center.
Patients: Ten adult patients with mild to severe hearing loss with pure-tone average (PTA) of > 30 dB and word recognition scores of < 80% in both ears.
Intervention(s): Subjects completed the AzBio Sentences test and the Consonant-Nucleus-Consonant (CNC) word test for each speaker type. Subjects were randomized regarding through which speaker the tests were administered first. All tests were completed for the first speaker before switching to the second speaker. The AzBio and CNC word tests were conducted in quiet at 50 dB and 70 dB SPL. The AzBio was also conducted in noise at +10 SNR.
Main Outcome Measure: Speech recognition, as measured by the AzBio Sentences test and the CNC word test in the sound field.
Results: Significant gains in speech recognition were associated with the HSS versus conventional speaker for all test conditions at 70 dB SPL. Median AZBio scores increased from 0.0% to 34.9% (p=0.008) in quiet, and from 1.8% to 51.6% in noise (p=0.008). Median CNC whole word test scores increased from 0.0% to 54.0% (p=0.004) and median phoneme test scores from 4.0% to 63.4% (p=0.004).
Conclusions: HSS demonstrates highly significant improvement in unaided speech recognition over conventional speakers at 70 dB SPL, including in background noise, in those with mild to severe hearing loss.
Introduction
In 1963, Peter Westervelt was the first to theorize that highly directional receivers and transmitters may be constructed utilizing the nonlinearity of a medium to transmit an acoustic signal on a narrow beam over great distances (Westervelt, 1963; Berktay & Leahy, 1974; Bellin & Beyer, 1962). This effect was initially observed experimentally in water in 1972 by Muir and Willette and in air by Bennett in 1974. The effort to transform this research into a consumer product required both an increase in sound intensity and a reduction in distortion. Piezoelectric crystals (Gallego-Juarez, Rodriguez-Corral, Gaete-Garreton, 1978) and films (Sussner, Michas, Assfalg, HunkLinger, & Dransfeld, 1973; Ambrosy, & Holdik, 1984; Wang & Toda, 1999) were shown to produce airborne ultrasound with sufficient efficiency and intensity to be useful for parametric audio. Recently, the reduction of audible distortion through the application of high-speed digital signal processing and proprietary filtering techniques led to the commercialization of a parametric audio device.
Utilizing these innovations in a commercial product, HyperSound® Audio System (HSS) employed Polyvinylidene Fluoride (PVDF) emitters (speakers) (Figure 1) and proprietary digital signal processing to produce a focused column of high-fidelity sound. Considered a “directed audio” device, the HSS works by first electronically converting audible information onto ultrasonic frequencies, well-beyond the range of human hearing. The acoustic signal is reproduced using an efficient PVDF emitter and transmitted in a beam of silent ultrasonic energy. The nonlinearity of air demodulates this acoustic signal, thus reproducing the audible information in a narrow beam, such that it is heard only by those in the targeted area.

Figure 1. HyperSound® Audio System (HSS) with Polyvinylidene Fluoride (PVDF) emitters (speakers).
Unlike a conventional audio speaker, sound is not created omni-directionally at the speaker (emitter) surface but is created within a narrow, directional air column (Figure 2). Because sound can be transmitted in this narrow beam over a relatively long distance without a reduction in intensity, the HSS audio is not prone to degradations from ambient noise or reverberation. As a result, unlike conventional audio speakers, HSS maintains a high-fidelity audio signal at the same intensity level over a relatively long distance for listeners who are positioned in the beam.

Figure 2. Depiction of narrow, directional air column generated by HSS allowing high-fidelity audio signal at the same intensity level over a relatively long distance for listeners who are positioned in the beam.
HSS is designed for use in the home, classrooms, lecture halls, or business and may be beneficial for both normal hearing and hearing-impaired listeners. It is intended to be used either with or without hearing aids in order to improve overall clarity of speech with home audio devices, such as the television, as its primary application.
The safety of HSS has been systematically evaluated. In comparison to other medical uses of ultrasound, such as ultrasonography or high-intensity focused ultrasound (HIFU), HSS delivers less than 1/12,000th the power density to the body compared to any other application and is well within the limits of human safety (Nelson, Fowlkes, Abramowicz, & Church, 2009; Haar & Coussios, 2007; Jewell, Solish, & Desilets, 2011), including standards set by the Occupational Health and Safety Administration (OSHA).
Preliminary, largely anecdotal, testing on subjects with and without hearing loss, as well as those with and without hearing aids, has shown a strong preference for HSS compared to a conventional TV speaker. These early, informal reports have shown improved comprehension of dialogue and improved clarity of speech for listeners using the HSS. In one internal, single-blind test in which participants listened to approximately 30 seconds of a movie clip with background noise through the HSS and conventional speakers sequentially, and in random order, nearly 74% of unaided subjects and 78% of aided subjects reported a preference for HSS over the conventional speakers.
In addition, preliminary testing, comparing the HSS to a conventional speaker, showed improvements in speech understanding ability for many listeners. These limited results hold promise that HSS may be a viable solution for patients with a range of hearing loss and warrants further study. The objective of this study was to compare speech understanding performance between the HSS and conventional speakers for a group of patients with hearing loss.
Methods
Participants
Participants were eligible for the study if they had a four-frequency pure-tone average (PTA) of > 30 dB, and a maximum word recognition score (PBmax) on the Northwestern University Auditory Test No. 6 (NU-6) or the Central Institute for the Deaf (CID) W-22 of ≤ 80% in both ears. Ten adult patients who had mild to severe hearing loss were deemed eligible for the study. Patients with cochlear or middle ear implants or extended wear hearing aids were not eligible.
Equipment
All testing was completed at the California Hearing & Balance Center in LaJolla, CA. Standard, calibrated equipment was used to complete the audiological assessment on all participants. The audio systems compared were the HyperSound audio system (amplifier and two emitters.) and a conventional audio system (Logitech X-240 stereo amplifier and two speakers).
Outcome Measures
The primary outcome was speech understanding ability, as measured by the AzBio sentences test (Spahr, 2012) and the CNC word tests (Peterson & Lehiste, 1962). Both are standard objective measures of speech understanding used in clinical practice to assess the performance of adults with normal hearing sensitivity, hearing impairment, or those with cochlear implants. Both the AZBio and CNC word tests have been validated and are clinically available.
The AzBio sentences consist of 15 lists, each containing 20 sentences, for use in the clinical evaluation of patients with normal hearing sensitivity, sensorineural hearing loss of varying degrees, and cochlear implant users. A unique set of eight lists was included in the Minimum Speech Test Battery (MSTB), used for the evaluation of cochlear implant candidates; lists from this subset were utilized in this study. Each AZBio list contains 20 sentences that range in length from four to 12 words. Using standard procedures, participants listened to each sentence and were asked to repeat what was heard. The AZBio test score equaled the total number of words correctly repeated, expressed as a percentage.
The CNC word test consists of ten lists of 50 monosyllabic words, each with three phonemes: a beginning consonant sound, a nucleus (vowel) sound and an ending consonant sound. Similar to the AZBio, the CNC word test was conducted using standardized procedures in the sound field. Two separate scores were calculated: the percent of total phonemes correct and the percent of words with all three phonemes correct, each expressed as a percentage.
Procedures
After signing an informed consent form, baseline hearing level was determined by testing pure-tone air conduction thresholds at 250-8000 Hz. In addition, tympanometry was conducted to establish normal middle ear function at baseline. Demographic data and hearing loss history was recorded.
Speech audiometry was conducted in the sound field using the two tests listed above at intensity levels of 50 dB SPL and 70dB SPL, respectively. The speech tests were delivered through a calibrated audiometer. Testing was conducted by placing each participant two meters away from the speaker/ emitter at a zero degree azimuth, as this is thought to be a common arrangement in which people watch television at home.
The output from each of the two speaker/emitter systems was carefully matched with a 1kHz tone using a hand-held Radio Shack sound level meter (SLM; 33-2050) using A-weighting. This device is only sensitive to regular audio frequencies, which prevents false signals created by distortion from high levels of ultrasound. To further avoid saturation from ultrasound, the SLM was oriented at 90o from the face of the HSS emitter which reduces incident ultrasound without affecting the baseband measurement. Above 1kHz, the frequency response from hypersound is flat within 6dB to 10kHz. This ensures that the sound pressure level at the position of the listener remained consistent for all tests.
This same SLM orientation technique was used for verification of a consistent intensity level when using the conventional speakers. Care was taken to ensure participants sat in the exact same position for all testing. All data was collected and recorded during a single study visit by a licensed audiologist.
Participants completed the AzBio sentences test, followed by the CNC word test. Each participant completed speech audiometry delivered in the sound field through the HSS emitters and once through conventional speakers. The order in which the testing was completed (speaker or emitter) was randomized. Participants were blinded at all times as to which speaker/emitter system was being used for assessment. All tests were completed in their entirety in the following order before switching to the second speaker/emitter system:
1. AzBio Sentences Test
a. One 20-sentence list in quiet at 50 dB SPL
b. One 20-sentence list in quiet at 70 dB SPL
c. One 20-sentence list in noise at 70 dB SPL+10 SNR
2. CNC Word Test
a. One 50-word list in quiet at 50 dB SPL
b. One 50-word in quiet at 70 dB SPL
Statistical Analysis
All patient demographics, baseline PTA, and other relevant baseline characteristics are presented using standard descriptive statistics. Continuous variables are reported using appropriate measures of dispersion and central tendency (means, medians, ranges and standard deviations) while categorical variables are summarized as number and percentage of the total study population.
The AzBio Sentences Test scores obtained for the HSS and acoustic speakers are summarized (means, medians, ranges and standard deviations), and compared using the Wilcoxon Signed Rank test for each of the conditions under which they were administered.
Two separate scores are calculated for the CNC word test: the percent of total phonemes correct and the percent of words with all 3 phonemes correct. Scores obtained for the HSS and conventional speakers are summarized (means, medians, ranges and standard deviations), and compared using a Wilcoxon Signed Rank test for each of the conditions under which they were administered.
Results
Baseline characteristics for all 10 participants are presented in Table 1. There were six males and four females with a mean age of 75 years. Mean PTA was 55.6 dB HL in the right ear and 57 dB HL in the left. All participants were Caucasian.
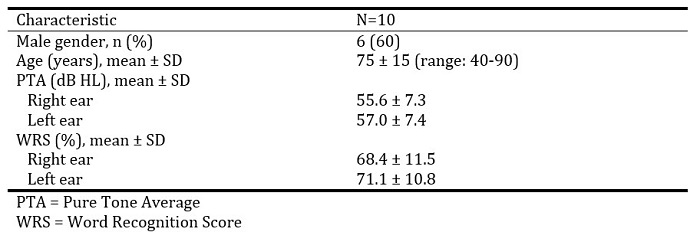
Table 1. Participant baseline characteristics.
The AzBio Sentences test and CNC word test scores for both the HSS and conventional audio speakers are presented in Table 2. There were significantly higher scores associated with the HSS compared to the conventional speaker technology at 70 dB SPL for both tests. Although there appears to be a slight trend toward improvement in scores obtained with the HSS at 50 dB SPL, the improvement was not statistically significant.
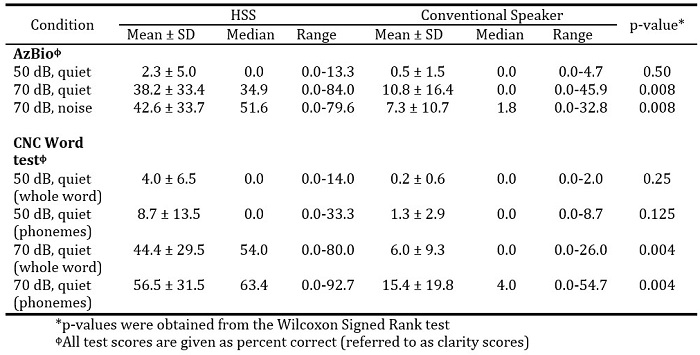
Table 2. Speech recognition scores: HSS vs. conventional audio speakers.
Discussion
Participants experienced significantly improved speech intelligibility scores when listening to sound through the HSS compared to the conventional speaker at 70 dB SPL in a controlled, laboratory environment. This improvement in speech intelligibility at 70 SPL for the HSS condition was statistically significant (p-value =0.008 level) for conditions of quiet and noise (+10 dB SNR). Although not statistically significant, it is worth noting that speech recognition scores were slightly better in the noise condition than in quiet. Given the test conditions and speech tests employed, this result remains unexplained and warrants further study.
While there is not a significant difference in speech understanding performance between the HSS and conventional speakers at 50 dB SPL, this was likely due to the participant’s degree of hearing loss and the low presentation level, which was inaudible to most of the participants. On the other hand, the difference in performance between the HSS and conventional speaker condition for 70 dB SPL input levels was significant and warrants further consideration.
One reason that participants experienced greater speech intelligibility with the HSS may be due to the precise targeting of sound within a narrow beam. Unlike a conventional audio speaker, which disperses sound omni-directionally from the speaker surface, the HSS creates sound along and within a tight, directional air column. The precision targeting of the HSS significantly minimizes the effects of ambient noise and reverberation, so the sound beam maintains a clear, high-fidelity audible signal over a relatively long distance. Another explanation relates to the frequency response of the HSS compared to conventional speakers. It is possible that the HSS more effectively transmits a broader bandwidth signal with more high frequency information relative to the conventional speaker. Given the positive effects of additional high-frequency energy on speech intelligibility (Hornsby, 2004), it is possible the HSS is able to provide greater audibility of high-frequency sounds, which contribute to improved speech understanding. Both of these explanations require further, systematic investigation.
The HSS produces audio by using the natural nonlinear properties of air, thus producing sound in the air rather than on the surface of a speaker. This allows the listener to receive the transmitted sound before reverberation or ambient noise interferes with the acoustic signal. Traditionally parametric audio produces an audible but highly-distorted audio signal due to the use of an amplitude modulation (AM) scheme. In this process, the carrier is multiplied by the desired audio signal. For every frequency applied, two ultrasonic frequencies are produced. This results in a theoretical best-case distortion of 50%. With complex signals, the results are worse. HyperSound used in this study features proprietary signal processing allowing for single sideband (SSB) modulation.
This results in a one-to-one mapping of input audio frequencies to output ultrasound frequencies. This allows for perfect (0% distortion) reproduction of pure-tone input and significantly increased performance for complex waveforms. This allows for higher-fidelity performance from HyperSound relative to any previous parametric audio system.
These results suggests that individuals with mild to severe hearing loss experience a significant improvement in unaided speech recognition when listening to speech through the HSS relative to a conventional audio speaker at 70 dB SPL, including in the presence of background noise. This may have significant implications for improvements in quality of life of patients with a range of hearing losses.
A second generation HSS audio device utilizing electrostatic film configurations as an ultrasonic transducer is currently being clinically validated as a higher-fidelity device than the first generation HSS described in this study. Work is also underway investigating the unique properties of ultrasonically transmitted sound for a variety of hearing losses with and without amplification. These early results presented here suggest that the HyperSound System, a new category of “directed audio” technology dispensed through the professional hearing healthcare channel, has merit as a hearing solution for individuals with hearing loss.
Acknowledgments
This research was supported by Turtle Beach Corporation, San Diego, California. Thank you to Brian Taylor, AuD, Senior Director of Clinical Affairs, Turtle Beach Corp. for suggestions to the manuscript.
References
Ambrosy, A. & Holdik, K. (1984). Piezoelectric PVDF films as ultrasonic transducers. Journal of Physics E: Scientific Instruments, 17(10), 856-859.
Bellin, J. L. S., & Beyer, R. T. Experimental Investigation of an end-fire array. Journal of the Acoustical Society of America, 24, 1051-1054.
Bennett, M. B., & Blackstock, D. T. (1974). Parametric array in air. Journal of the Acoustical Society of America, 57(2), 562-568.
Berktay, H. O., & Leahy, D. J. (1974). Farfield performance of parametric transmitters. Journal of the Acoustical Society of America, 55(3), 539-546.
Gallego-Juarez, J. A., Rodriguez-Corral, G, & Gaete-Garreton, L. (1978). An ultrasonic transducer for high power application in gasses. Ultrasonics, 16(6), 267-271.
Haar, G. T., & Coussios, C. (2007). High intensity focused ultrasound: physical principles and devices. International Journal of Hyperthermia, 23(2), 89-104.
Hornsby, B. W. Y. (2004). The Speech Intelligibility Index: What is it and what's it good for? Hearing Journal, 57(10), 10-17.
Jewell, M. L., Solish, N. J., & Desilets, C. S. (2011). Noninvasive body sculpting technologies with an emphasis on high-intensity focused ultrasound. Aesthestic Plastic Surgery, 35(5), 901-912.
Nelson, T. R., Fowlkes, J. B., Abramowicz, J. S., & Church, C. C. (2009). Ultrasound biosafety considerations for the practicing sonographer and sinologist. Journal of Ultrasound in Medicine, 28(2), 139-150.
Muir, T. G., & Willette, J. G. (1972). Parametric acoustic transmitting arrays. Journal of the Acoustical Society of America, 52, 1481.
Peterson, G. E., & Lehiste, I. (1962). Revised CNC lists for auditory tests. The Journal of Speech and Hearing Disorders, 27, 62-70.
Spahr, A. J., Dorman, M. F., Litvak, L. M., Van Wie, S., Gifford, R. H., Loizou, P. C., et al. (2012). Development and validation of the AzBio sentence lists. Ear and Hearing, 33(1), 112-117.
Sussner, H., Michas, D., Assfalg, A., HunkLinger, S., & Dransfeld, K. (1973). Piezoelectric effect in polyvinylidene fluoride at high frequencies. Physics Letters A, 45A(6), 475-476.
U.S. Department of Labor, Occupational Safety and Health Administration. OSHA Technical Manual, Section III: Chapter 5 - Noise Measurement. Retrieved from www.osha.gov
Wang, H., & Toda, M. (1999). Curved PVDF airborne transducer. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, 46(6), 1375-1386.
Westervelt, P. J. (1963). Parametric acoustic array. Journal of the Acoustical Society of America, 35(4), 535-537.
Citation
Mehta, R., Mattson, S., & Seitzman, R., & Kappus, B. (2015, August). Speech recognition in the sound field: directed audio vs. conventional speakers. AudiologyOnline, Article 14901. Retrieved from https://www.audiologyonline.com




