
Learning Outcomes
After this course learners will be able to:
- List current Oticon Medical Ponto processors.
- Describe the fitting range of processors and candidacy.
- Explain bone conduction output versus air conduction output.
Introduction
The current family of Oticon Medical processors is the Ponto 3, which is the most powerful family of abutment level processors. When developing new technology, patients' needs are always our starting point. We aim to help improve outcomes for users of bone anchored hearing systems. We do this from a holistic perspective to cover all different aspects that are important to the users and their quality of life. The greatest potential for overcoming challenges for users is found outside of the clinical situation in their everyday lives; this is where sophisticated sound processing really comes into play. Our starting point for improving bone anchored hearing systems is always the users' and their typical challenges. We know that all bone anchored users can benefit from more power and therefore we constantly strive to focus our development to make the products more powerful to deliver better patient outcomes.
Ponto 3 is our third generation of bone anchored processors. The Ponto 3 family includes the Ponto 3, the Ponto 3 Power, and the Ponto 3 SuperPower, which is the first 65 dB abutment level processor. Our engineers and experts in transducers were able to provide the power of the Ponto 3 SuperPower and make it a single unit processor, so there's no need for the user to wear any additional elements. Sound quality is a complex subject and is very different from individual to individual. Ponto features great sound quality. Users typically report that speech is clear, crisp, and natural in quality.
To deliver Ponto sound quality when developing our products, we incorporate three main fundamentals:
- Output: Higher output across the entire bandwidth provides access to an increased dynamic range
- Frequency Bandwidth: Frequency bandwidth is needed for a full spectrum of sound and is particularly important for speech understanding.
- Clarity: In order to better recognize sound, users need to know what is happening around them. This is where advanced sound technology makes a difference.
Ponto 3: Output
Today, we're going discuss the importance of device output. There are some common patient challenges or concerns we try to address when developing our products. Our four main areas of focus include:
- Offering safe and reliable treatment options
- Providing solutions for overcoming listening challenges
- Keeping up with modern communication solutions
- Promoting healthy skin principles
Our starting point for improving our bone anchored hearing system is always the users and their typical challenges. We try to figure out ways to alleviate these issues. When asked to prioritize their daily challenges, patients rate speech understanding and clear sound as their highest priorities related to perceived sound quality. Understanding speech in difficult listening situations is the number one complaint patients report.
A wide range of sounds can be heard in the environment, from the lowest hearing thresholds in quieter settings (e.g., a residential suburban neighborhood), to the highest loudness discomfort levels (LDLs) and pain thresholds in noisier settings (e.g., an airport or rock concert). For normal hearing people, the entire range is available, and LDLs are truly very loud. If we take a patient who has a normal hearing cochlea but a large air-bone gap (as in cases of conductive hearing loss), their typical dynamic range is still relatively large (around 95 dB HL). Of course, when there is cochlear impairment involvement, in most cases this dynamic range is reduced.
All bone anchored systems have limited output by nature. They can all transmit sounds up to a maximum force output (MFO). MFO is typically low and well below the user's loudness discomfort level. Sound levels that exceed the MFO will be distorted, meaning the input dynamic range will not accurately be reproduced. However, we are able to provide a larger dynamic range of sounds with fewer distortions when we use a more powerful sound processor (i.e., processors that have higher MFOs).
Most people want to hear sounds loudly, as this is a natural representation of their relative loudness. It is always appropriate to allow for more output for bone anchored system devices. It's always appropriate to fit patients with devices with large outputs when we are working with bone anchored hearing systems.
When we are talking about bone anchored systems, we are talking about max force output as opposed to the power of output as used with traditional air conduction hearing aids. Bone-anchored devices do not have the ability to make incoming sounds too loud for our users. Even with SuperPower bone anchored systems, the MFO is well below the user's LDL. Therefore by providing a patient with more output, they are provided with a wider dynamic range at no risk of causing damage with over amplifying. Every bone anchored system patient can benefit from these higher MFOs, such as in the Ponto 3 SuperPower.
With conventional air conduction hearing aids, SuperPower is associated with big hearing losses that require a lot of amplification, and therefore a high maximum power output (MPO). Subsequently, the software provides a warning that you must take care of fitting these instruments because it's possible to damage hearing with too loud of an air conduction stimulus. This does not apply with bone-anchored hearing aid systems.
Bone-anchored systems have a certain maximum output, such that loud sounds can only be reproduced to a certain level per device. Figure 1 shows a comparison of some historical devices and their output limitations. If you take a look at this chart, the loudest sound that the device can produce is below the patient's LDL, therefore their dynamic range is compressed due to the limits of the BAHS device's maximum output. Our focus is on making each device more powerful, thereby increasing the maximum output.
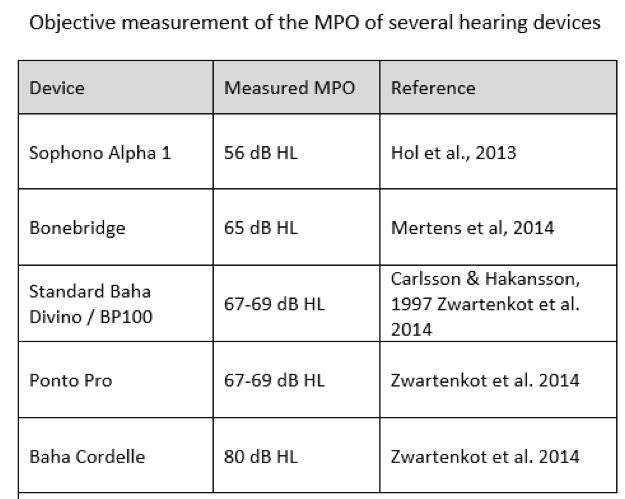
Figure 1. Objective measurement of the MPO of several hearing devices.
There is no risk of overfitting or overamplifying by using bone anchored powered devices well below the LDL. Gain is prescribed to the hearing loss and can be set low enough for even minimal conductive hearing losses. The patient is still able to increase the volume by 10 dB.
Since first introducing the Ponto to the market, we have continually worked to increase the output of the sound processor. This increases over the full bandwidth. Through the progression of our product generations, from the Ponto Pro to the Ponto 3 to the Ponto 3 Power, our output has increased. With the introduction of the Ponto 3 SuperPower, we can further increase this output, providing an even better possibility for loud sounds to be heard loudly, but not uncomfortably (Figure 2). We have increased the output by 14 dB since first arriving on the scene with the Ponto Pro. The Ponto 3 SuperPower has an output of 135 dB.
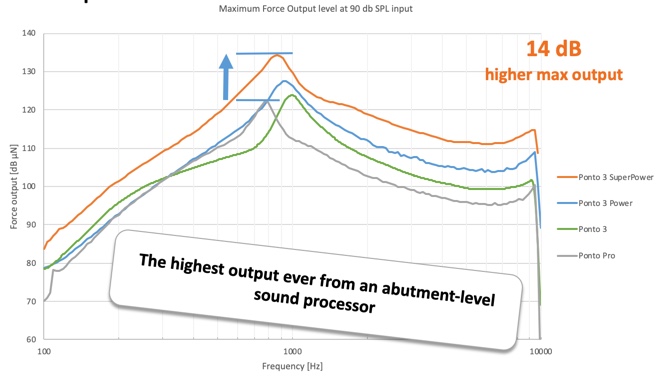
Figure 2. Output increase across Ponto generations.
In Figure 3, we can see the fitting ranges of our current Ponto 3 processors. The Ponto 3 has a fitting range up to 45 dB. The Ponto 3 Power has a fitting range of up to 55 dB. The Ponto 3 SuperPower has a fitting range of up to 65 dB. Remember: these are the recommended fitting ranges, but everyone can benefit from the more powerful device to expand their dynamic range.
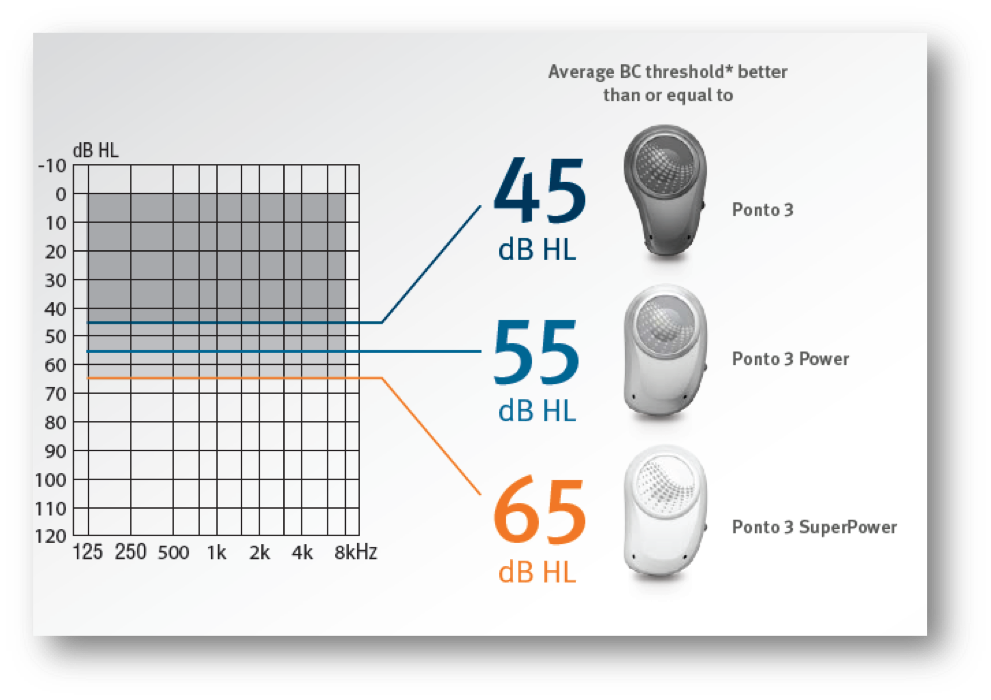
Figure 3. Ponto fitting ranges.
This increase in maximum output of the Ponto 3 SuperPower is a result of the perfect match between transducer design know-how, and over 100 years of audiology expertise within the WDH group, Oticon and Oticon Medical. In short, it is a combination of:
- Ultra drive technology (a step-up conversion), which boosts the transducer and maximizes the output.
- Inium Sense platform technology, which allows us to minimize the feedback with our Dynamic Feedback Cancellation System (DFC). With the Inium Sense Feedback Shield, when critical acoustic events occur, the feedback control lifts the Ponto 3 out of the feedback risk area.
- Speech guard, which allows the variations in amplitude between sounds to preserve natural detail and nuances of speech in everyday life.
- Battery management system. We use a high power battery with high performance but low battery consumption. There's a supervisor battery consumption which reduces the power when needed. There are also alerts to let your patients know when the batteries are low.
This combination of technology allows us to keep the size of the processor down while still being able to deliver power.
Dynamic Feedback Cancellation (DFC) System
If you want to provide high amplification, you need the feedback management system. Feedback results from vibrations from the skull feeding back into the instrument, which is patient dependent. The feedback manager defines the feedback margin or limits for the patient and is measured in the clinic. This allows for continuous gain control to avoid feedback.
Our dynamic feedback cancellation system works in everyday situations. DFC uses two steps:
- A phase inversion, which takes care of known feedback before it occurs
- Frequency shift, which breaks the feedback path
In cases of softband and headband users, the perceived loudness sound is weaker due to the skin and tissue attenuation as compared to abutment solutions. SuperPower will be better able to compensate for that loss in signal. In cases of single-sided deafness, we want to match the patient's better ear (which theoretically has a normal LDL and also a normal large dynamic range). We want to match their normal loudness perception in the better ear. The way to do that is to give them a large dynamic range with a SuperPower product. Patients with conductive and mixed hearing losses of all degrees can benefit from the larger dynamic range.
Ponto 3 SuperPower is not a niche product. It's mainstream. Soft sounds should be soft and loud sounds should be loud. We aim to preserve as much of the patient's dynamic range as possible. Ponto 3 is a single unit processor for power and quality and reliability. There's no need to wear an additional piece. It's all abutment level. It's discrete, small, and the battery lasts a long time.
Output: Direct Drive vs. Skin Drive
From a performance perspective, bone anchored systems can be classified into two groups: direct drive (percutaneous) transmission options and skin drive (transcutaneous) transmission options.
As shown in Figure 4, there is significantly more output provided with a direct drive system (represented by the orange color) as compared to the skin drive (shown in yellow). The direct drive allows for increased low frequencies, for better loudness sensation and voice quality, more high frequencies for delivery of important speech signals, and also a wider frequency bandwidth for improved speech perception, sound quality, and speech in noise understanding.
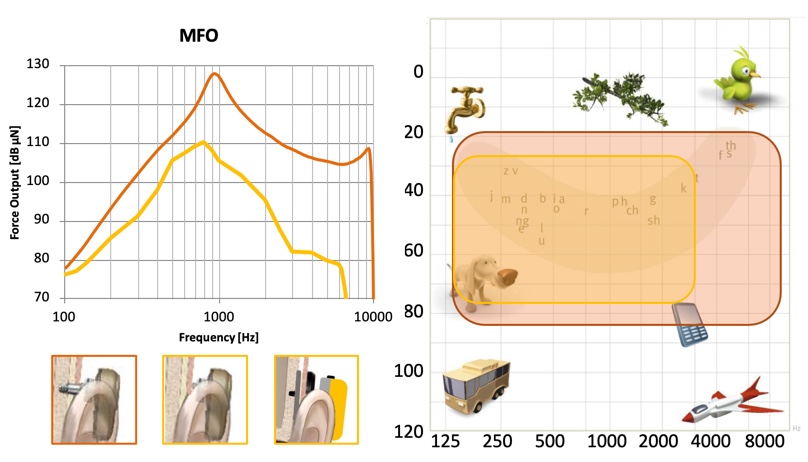
Figure 4. Direct drive vs. skin drive.
Some benefits of direct sound transmission are that:
- Sounds are attenuated in skin transmission solutions, even with softband correction factors in the software.
- Direct sound transmission systems can provide an extra 10 to 20 dB of output in the mid to high-frequency range.
- The mid and high-frequency range contains the most important sound information for speech understanding.
There are some additional differences between percutaneous and transcutaneous systems.
- Direct-drive systems send vibrations via a direct route to the bone. With skin drives (such as softband, headband, test band or passive transcutaneous solutions with an implanted magnet), vibrations are sent through the skin and tissue to the bone. This suffers from skin and tissue attenuation.
- There is a minimal physical sensation of the device when the patient is wearing a direct drive system. With skin drives, there is a constant awareness of the processor due to the pressure it puts on the skin.
- With direct drives, MRI shadowing is nominal, producing about a 10-millimeter artifact. In contrast, with skin drives, MRI shadowing is significant, producing about a 150-millimeter artifact. This is important to consider when we are working with patients that may require MRIs.
- With direct drive systems, tissue preservation surgery leaves only a small post. With skin drives, surgery removes a significant area of hair, skin, and tissue (if you're using a magnetic option).
Another benefit of direct drive systems is that they offer upgradability, regardless of the possible changes in hearing.
In terms of transmission, direct drive devices are the most efficient, since no attenuation occurs from the skin and tissue dampening. A person who uses a skin drive system, due to their limited output, is at risk of missing important speech sounds. The skin and tissue absorb the energy causing a lower perceived output level. More power is needed in order to have the same perceived benefit with a skin drive device when compared to a direct drive device.
Study #1. A study was conducted by Dr. Andrea Pittman in order to assess the speed at which children could learn new nonsense words in different listening conditions. The subjects were 17 children, 16 with conductive hearing loss and one with single-sided deafness. The subjects were asked to perform a task in two different listening scenarios. One condition was with direct drive (the processor was worn on their abutment); the other condition was via skin drive (the processor was worn on a softband). The task was to learn six new words. The results of this study were significant, demonstrating two and a half times faster learning with direct drive systems. Children needed far fewer repetitions of the words before learning when their processors were worn on their abutment versus softband (Pittman, 2019).
I'm going to play a short video from the researcher, Andrea Pittman.
Study #2. Another study was performed, this time by Dr. Thomas Lunner and Oticon Medical. Once again, the aim of the study was to assess the difference in performance with direct drive vs. skin drive transmission using a memory and recall (SWIR) test. There were 16 adult subjects with conductive or mixed hearing loss. Like the previous study, these subjects wore their devices under two different listening situations: one on their abutment and one on a softband. The signal noise ratio at which this was performed was adjusted for each participant to achieve 95% correct recognition in the poorer condition. They did this wearing their softband condition to determine the signal and noise ratio to perform the test.
The participants wore two sound processors at the same time, one connected to their abutment and one on the softband, however, only one processor was functioning at a time. They were given the following seven sentences and asked to recall the last word of each sentence.
- Everybody wears sunglasses.
- He is still lying on the sofa.
- The student will write a long report.
- The whole town came to the wedding.
- His daughter wants to go to college.
- Yesterday was the film’s premiere.
- The factory port was not closed.
In the end, the results showed a significant improvement using direct transmission over skin transmission. There was a 13% improvement of words recalled correctly when using a processor connected to their abutment (a direct drive condition). Listeners' ability to recall was significantly higher (52%) with the sound processor connected to their abutment, compared to using a softband (46%).
This study suggests that direct sound transmission provides more sound to support the brain's cognitive processes, which reduces the effort spent on listening. If the brain is not getting the right sounds to work with, it takes intense effort to create meaning. Transmitting sound via the Ponto implant to the temporal bone (without dampening from the skin) yields a better signal quality and less effortful processing (Lunner et al., 2016).
I'm going to play a short clip from this researcher, Thomas Lunner.
Output: Fitting Examples
If we take a look at input versus output, we can see why all bone anchored users can benefit from devices with higher maximum force output, like the Ponto SuperPower. If we provide amplification with a limited max output, we run the risk of reaching saturation levels, which can create distortion. When we get saturation at the input level, sounds above the saturation levels cannot naturally be reproduced, and this creates distortion on the output level, causing a reduction in the dynamic range, and a reduction in environmental and speech sounds for the user. By creating a more powerful device (i.e., an abutment level processor), we are able to increase and improve the dynamic range, resulting in more power across the entire frequency, not just at some frequencies. This allows for more input and higher saturation levels. It also allows for increased output levels without distortion.
When comparing a device with a 45 dB fitting range to a Ponto 3 SuperPower with a fitting range of 65 dB, the output is increased by 10 dB and we have less risk of distortion overall. A larger proportion of the dynamic range is able to be maintained, and there is less limitation at both the input and output level. We need to have adequate room to be able to amplify optimally.
Let's look at input and output in relation to a device with limited max force output. If a patient with a conductive hearing loss is using a device with a low max force output, the input reaches saturation levels, which translates into distortion detected by the patient and the output. We want to maintain the natural dynamic range as much as possible in order to adequately reproduce environmental and speech sounds for the user.
When we use another device with a larger or higher max output, we are able to maintain a larger dynamic range. The saturation level on the input also increases. In a larger proportion of the dynamic range, dynamics of the environment and speech are reproduced without being limited. This is particularly important when we're considering patients with significant hearing losses, specifically in cases of single-sided deafness or in patients with skin driven devices (processors worn on softband, headbands or other skin drive configurations). Again, we can see input with lower max force output the saturation level is low. If we fit a processor with a higher MFO, saturation level is increased on the input side and so is the level of distortion.
Study #3. For the third study we will examine, the principal investigator was Oticon Medical. This study took a look at processors with different outputs and the effects on patients' listening effort. Listening effort was measured based on pupil dilation, as it has been shown that when we apply more effort, our pupils get larger. There were 21 adult participants. Each participant was tested with three different processors, and each processor had a different MFO. The task was to listen and repeat back sentences, during which time the pupil size was measured. In the end, the results showed that when patients wear more powerful devices that have more output dynamic range, they exert less effort while listening (Bianchi et al., 2019).
I'm going to play one more video from researcher Federico Bianchi.
Frequency Bandwidth
In order to deliver the renowned Ponto sound quality, frequency bandwidth is key. The frequency bandwidth is needed for a full spectrum of sound and particularly important for speech understanding. Ponto has the industry's widest frequency bandwidth. The Ponto 3 has a bandwidth of 200-9500 Hz, compared to a competitor, which has a bandwidth of 250 to 7000 Hz. That's a 38% wider frequency bandwidth with the Ponto 3. The Ponto 3 Power and Ponto 3 SuperPower devices have an even broader bandwidth, both going up to 9600 Hz.
A study was conducted to determine the number of trials needed to get 70% words correct. This study was done with hearing aids, but looking at the bandwidth. The results of the study suggested that children listening to words under extended bandwidth conditions learn new words three times more quickly when compared to children listening to words under a limited bandwidth. This knowledge highlights the importance of extended bandwidth and provides a valuable insight into our sound processor development. To develop normal language skills, children need access to the clearest most complete auditory signal and the widest dynamic range. [CITATION NEEDED, Slide 50]
Clarity
Another important consideration for optimal patient benefit is clarity. We need to make sure all the information we are giving to the patient is perceived clearly. The sound processor should support patients in all listening situations they encounter, from noisy sporting events to family dinners and everything in between. This is where the most advanced sound technology can make a difference.
The Ponto 3 features our FreeFocus directionality system, which is designed to help the brain to focus while continuing to orient and separate sounds. FreeFocus is an optimized directionality system which is categorized by the availability of two omnidirectional microphones and the automatic directionality system.
A typical user spends 70% of the time in Omni mode [CITATION NEEDED, Slide 52]. As such, we wanted to focus on improving the situations that matter, instead of only looking at the most difficult listening situations. Therefore, we created a new mode: Speech Omni. This new mode aims to mimic the natural front focus of the pinna. Speech Omni is a light speech prioritization mode with enhanced front focus, in order to help suppress sounds from the back. In a 2016 Oticon Medical study, results revealed a 1.2 dB SNR improvement in speech understanding using the Speech Omni mode with Ponto 3 (as compared to using Ponto Plus in Surround mode). This is equivalent to a 15% improvement in speech understanding.
Another mode, Split Directionality, combines the best of both worlds, allowing the user to focus on the desired signal in front, while still providing awareness and sound inputs from the rear. This mode is a mix between omnidirectional and directional modes with the lower frequencies being in Omni and higher frequencies being in directional. This follows the same principle as Speech Omni, but with a lower cutoff at 1250 Hz. Split directionality is applied in moderate to noisy environments. Finally, our Full Directionality mode is fully directional, giving the user the most focus and help in difficult situations to prioritize the desired signal over others. These modes are all automatic and always occurring as the user is wearing them.
BrainHearing
If you have previously worked with Oticon hearing aid products, you may already be familiar with the concept of BrainHearing. Thanks to Oticon Medical's connection with Oticon hearing aids, we were able to take this concept and incorporate it into our bone anchored product development. If you aren't familiar with BrainHearing, at its core, it is based on a fundamental understanding of how hearing works and how the brain makes sense of sound.
Listening is complex. When we are listening, in order to achieve perception, there are multiple cognitive functions working at the same time, such as memory, executive function, and attention. The hearing loss only furthers this complexity. The concept of BrainHearing in the Inium Sense platform is intended to reduce the stress of listening for our patients. In order to achieve this, we need to provide the patient with optimal auditory and signal processing.
First of all, we want to power the brain. Hearing loss puts a lot of strain on the brain as patients are struggling to hear and make sense of sounds in noisy situations. We do all we can to take the effort out of listening and help the brain make sense of sound. We do this through deliberate choices we have made to provide a powerful sound quality to our users. By providing audibility and signal processing, we reduce the burden on the brain from hearing loss and give the users the power to participate in daily life, as well as the power to free up mental energy to focus on all the things they want to do like play, learn, work, socialize and have fun. It's especially important when we are considering children. We want to make sure we're empowering the children to participate and develop in life. BrainHearing is about making listening easy for every user. By reducing the listening effort that hearing loss puts on the brain, we free up mental energy for more important things.
We need to be able to provide audibility and signal processing that supports the brain's cognitive processes. Our Inium Sense chip delivers the increased processing power and advanced sound processing technology for improved signal clarity. This helps the brain to code sound and focus on the importance of hearing details. Direct Sound Transmission with a direct connection to the bone can provide an extra 10 to 20 dB of output in the mid to high-frequency range. This range contains the most important sound information for speech understanding.
Direct Sound Transmission and the Inium Sense platform are the prerequisites for delivering the output bandwidth and clarity users need to experience powerful sound quality. Direct Sound Transmission and the advanced Inium Sense platform sound processing are unique enablers for BrainHearing in bone anchored systems. BrainHearing is about the fundamental understanding of how hearing works and how the brain makes sense of sound.
When we think about hearing, we automatically think about the ears, but we know in fact that sound is heard and processed by the brain. There are four steps necessary for sound to be processed.
- Orientation: The brain uses all auditory inputs orient itself about its sound environment.
- Recognition: The brain needs to recognize sounds based on experience and gather meaning from what it hears.
- Focus: the brain has to know where to focus in noisy sound environments.
- Separation: the brain compares the sound it receives in order to separate them.
These four processes are the same regardless of if you have hearing loss or not, or if you need conventional air conduction hearing aids or a bone anchored system. Our goal is to help our patients learn faster and remember more all with less effort. We're able to more successfully do this by providing abutment direct drive solutions, which are shown to improve learning speeds, recall, and memory. We were also able to reduce the effort at which the patient must exert, by providing the industry's most powerful abutment level processor.
Summary and Conclusion
With our Ponto 3 family of processors, we are able to give patients optimal benefit by providing the following:
- BrainHearing™ for BAHS
- Direct Sound Transmission
- Inium Sense platform
- World’s first single-unit SuperPower
- Highest output ever from an abutment level sound processor
- Widest frequency bandwidth
- Wireless power
- Reliable performance
- First ever DSL-BC
Figure 5 shows the feature overview of our Ponto 3 family of products.
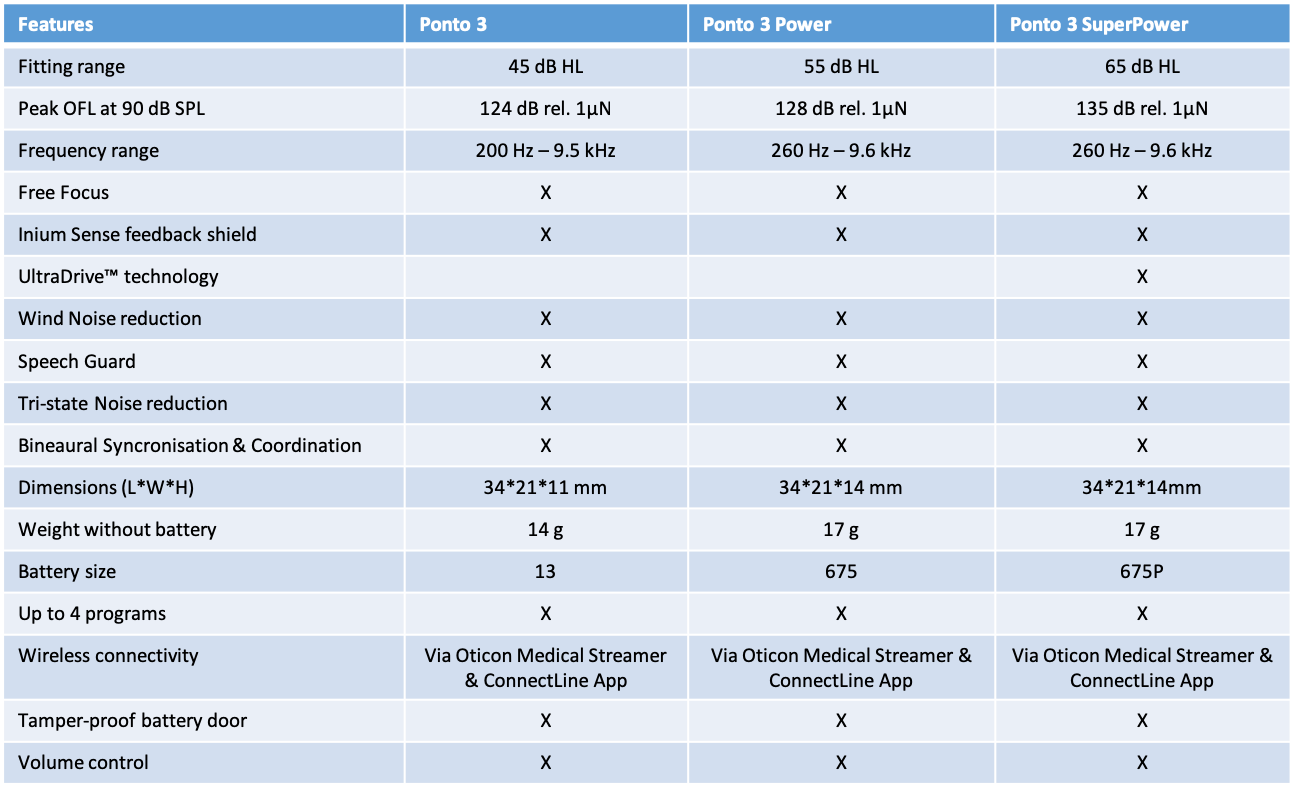
Figure 5. Feature overview, Ponto family.
For patients with a conductive loss, the higher MFO means better utilization of their dynamic range, along with more natural sound in louder listening environments. For patients with mixed hearing losses, the higher MFO gives them a larger dynamic range and also headroom in the device, so that more sounds are reproduced naturally without being limited. For our softband and headband users, a higher MFO helps to address the skin and tissue attenuation. Our single-sided deafness patients will be better able to loudness match sounds from the device to send the signal to the better ear.
As shown in the studies we reviewed earlier, direct drive transmission has been shown to improve the rate of learning in children two and a half times faster than skin transmission. Direct drive has been shown to improve memory with a 13% improvement in recall as compared to skin drive. Maximum force output comparisons have demonstrated a significant benefit of direct drive by reducing the listening effort while providing more power and more output.
In conclusion, the system we choose for our patients matters. It could have an impact on learning, remembering, and the effort necessary to listen and process stimuli heard in everyday listening environments. When choosing options for your patients, consider the best long-term solution for them. Especially with our pediatric patients, we need to pay close attention to the significant benefits of direct bone transmission. It is also important to counsel parents and caregivers regarding FDA guidelines for implantation and the appropriate age at which is it's optimal to move from a softband configuration to an abutment direct drive worn device.
References
Bianchi, F., Wendt, D., Wassard, C., Maas, P., Lunner, T., Rosenbom, T., & Holmberg, M. (2019). Benefit of Higher Maximum Force Output on Listening Effort in Bone-Anchored Hearing System Users: A Pupillometry Study. Ear and hearing.
Briggs, R., Van Hasselt, A., Luntz, M., Goycoolea, M., Wigren, S., Weber, P., ... & Cowan, R. (2015). Clinical performance of a new magnetic bone conduction hearing implant system: results from a prospective, multicenter, clinical investigation. Otology & Neurotology, 36(5), 834-841.
FreeFocus feature test report (2016), Oticon Medical report no 34425-00
Pittman, A. L. (2008). Short-term word-learning rate in children with normal hearing and children with hearing loss in limited and extended high-frequency bandwidths. Journal of Speech, Language, and Hearing Research. 51; 785-797.
Pittman, A. L. (2019) Bone conduction amplification in children: Stimulation via a percutaneous abutment vs. a transcutaneous softband. Ear Hearing (under review).
Lunner, T., Rudner, M., Rosenbom, T., Ågren, J., and Ng, E.H.N. (2016) Using Speech Recall in Hearing Aid Fitting and Outcome Evaluation Under Ecological Test Conditions. Ear Hear 37 Suppl 1: 145S-154S.
Wagener K, Josvassen JL, Ardenkjær R (2003) Desing, optimization and evaluation of a Danish sentence test in noise. International Journal of Audiology; 42: 10-17
Citation
Restivo, J. (2019). Power for everyone! AudiologyOnline, Article 24461. Retrieved from https://www.audiologyonline.com

