
Learning Outcomes
After the course, participants will be able to:
- Explain why listening is more effortful for those with hearing loss.
- Describe a few different ways of measuring the effort used to understand speech, and why this is relevant for real life situations.
- Discuss the limitations of maximum output of bone anchored devices, and how this affects different users of these devices.
Introduction
This course will present the scientific basis for BrainHearing and how that relates to the Ponto family products, and to bone anchored hearing devices in general. We strongly believe that a higher maximum output should be one of the most important decision factors for patients, and will discuss how different user groups will benefit from this.
In the first part of this presentation, we will talk about hearing and cognition, and how the two are related. We will also look at real-world listening situations that our patients may experience. Next, we will consider how we can revise our measurement methods to include cognition. Then, we will review the results of studies using bone anchored devices and novel outcome measures including cognition. In part two, we will go into further detail regarding issues related to bone anchored devices, discussing the maximum output of the device and how that affects different types of users. Lastly, we will consider how this can influence the way we counsel our patients.
Hearing and Cognition
First, I would like to start off with a task. Please read aloud the following words (Figure 1).

Figure 1. Cognition exercise.
Next, I would like you to do something slightly different. Using the same set of words, read the color of the text used for each word. When you compare your speed in reading text alone vs. saying the color of the text, you may have noticed that you perform slightly slower on the second task. Reading text is an automatic task. When we need to change gears and say the color, that requires a bit more thought; our brains need to work harder. Listening to and understanding speech is a similar concept. For people with normal hearing, the listening and understanding process is automated. For those with hearing loss, however, listening and understanding requires considerable effort.
The Listening Effort Framework
When we talk about speech understanding, we use something called the Listening Effort Framework (Figure 2). The Ease of Language Model was published by Ronnberg et al. (2013). When we listen, we have acoustic input; our ears transform that input into auditory representation in the brain. That auditory representation is compared to our templates that we store in long-term memory. If there is a direct connection of high similarity between the auditory representation and the template, we have a match and meaning, and therefore an understanding of speech. We call this the implicit processing pathway. It is a very automated response, much like reading does not require much effort.
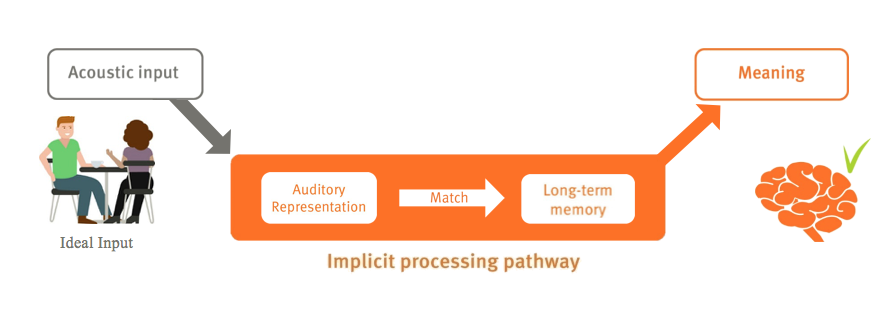
Figure 2. Listening effort framework: implicit processing pathway.
However, what happens if we take the same input, but introduce the information in a more acoustically challenging situation (e.g., one with a lot of background noise, or the speaker has a foreign accent, and the listener is trying to do several things at once)? In these difficult listening environments, we capture an auditory representation that is not very clear and cannot be directly matched to our long-term memory and the template we have stored. In that case, we use our working memory to make sure that we understand. We call this the explicit processing loop (Figure 3). The result, if it works, is the same: we pick up on the meaning of what is being said, but we do need to spend a lot of effort. We are required to spend our working memory on it, in order to resolve the differences between the auditory representation and the long-term memory. We see this difference between the implicit, or automated loop and the explicit, more effortful loop.
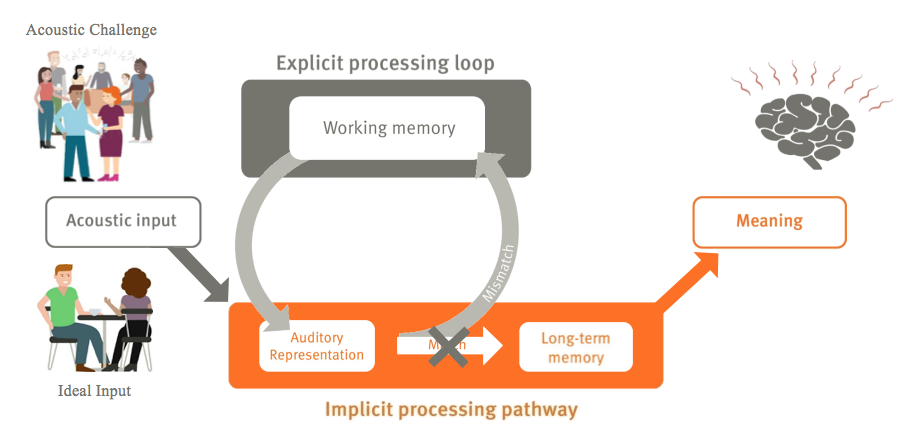
Figure 3. Listening effort framework: explicit processing loop.
Long-Term Effects of Hearing Loss: Research
With a normal hearing cochlea, you have a excellent auditory representation that you can match to your long-term memory. Whereas with a hearing loss, your auditory representation is worse; as such, you need to use your working memory actively to make sure that you understand the same information. Are there long-term effects of this type of effortful listening? This is a topic under research, but so far, the answer points to yes.
Two studies by Grossman et al. (2002); Peelle, Troiani, Grossman, Murray, and Wingfield (2011) show a relationship between hearing loss and increased cognitive load. Both studies used fMRI (Magnetic Resonance Imaging) to measure the impact on the brain. First, Peele et al. (2011) showed that in people with hearing loss, there is reduced language-driven speech activity in the primary auditory pathways. In other words, the area of the brain that is related to understanding more complex information and higher level functions is negatively impacted in those with poor hearing. Additionally, Grossman et al. (2002) found that people with hearing loss show an increase in compensatory language-driven activity in the prefrontal cortical areas, which are related to the working memory. Their limited acoustic input is compensated for with their working memory, which is visible in fMRI scans.
Lazard and Giraud (2017) intended to gain a better understanding of CI patients and candidates. Thier participants were given a visual task of looking at two words on a piece of paper, and they were asked if the words rhymed or not. Note that this was not an auditory task, but a visual task. Using fMRI, they scanned the participants' brains while performing this task. Compared to the brain scan which represents a sub-group of post-lingual deaf participants performing the same task. Interestingly, when you measure the speed and accuracy with which the participants perform this task, this subgroup of deaf participants performed better than normal hearing participants. This suggests that because of their auditory deprivation over many years, the deaf participants have recruited areas of the brain normally used for auditory stimuli, into the pathway used by visual stimuli. The long-term goal of this research indicates that these patients might be poor recipients of CI, simply because the parts of their brain that they normally would use for hearing have been taken over by vision instead. More studies are being conducted, but the evidence shows that the lack of auditory stimuli can most definitely affect the way our brain works.
Another study by Ronnberg, Rudner and Lunner (2011) was conducted using correlation, by measuring hearing loss for patients and also using different methods to measure their long-term memory. They found a strong correlation between the severity of hearing loss and long-term memory performance. In other words, the more significant hearing loss you have, the worse your long-term memory becomes. This holds true even if you correct for age. Clearly, hearing has long term effects on the brain.
The final study we will review was conducted by Liberman, Liberman and Maison (2015). Researchers looked at the inner hair cells of mice that had induced conductive hearing losses, similar to those we see with bone anchored patients. Looking at the cochlea of these mice with conductive loss, they observed the degeneration of inner hair cells in the synapses.
In summary, listening requires more effort for those with a hearing loss. With a hearing loss, you have a poor auditory representation than compared to normal hearing counterparts. Therefore, you have less automatized speech understanding, consequently requiring more activation of working memory in order to understand. Next, as supported by many research studies, we have seen that untreated hearing loss has long-term effects on memory and brain function. The next step is to see if treatment with a hearing aid, a bone-conduction device or cochlear implant affects this over time. As part of our ongoing research, we are working together with universities around the world to try and determine the best type of treatment to use.
Real-World Listening Situations
For part two of the presentation, we will look at the real-world "ecological" listening situations in which hearing impaired people typically find themselves on a daily basis. First, I will refer to some work that was conducted by Widex ORCA, in partnership with the research department at Jade University of Applied Sciences, in Oldenburg, Germany. They took 20 hearing impaired hearing aid users, and had them wear recording devices for several weeks to document all of the sound situations they found themselves in. The researchers then analyzed the resulting data. They categorized the different listening situations that each participant encountered (e.g., listening to TV, outdoors, department store, etc.). In almost all situations, the participants were in a positive signal-to-noise ratio. They were rarely in a situation where there was more noise than the target source, or the speaker based on Smeds, Wolters, and Rung (2015) findings. Speech-based situations average around 65 dB. If you look at the variations over time, in almost all situations, the variations are larger than the typical 30 dB, because there are noises and sounds occurring in the background, above and beyond speech. In most of the situations that we are in a large proportion of the time, we are at more than 65 dB.
Next, in the Oldenburg, Germany study, researchers asked the participants to rate their own speech intelligibility in four of the situations: at home, outdoors, leisure activities and work. The majority of users reported that they understood nearly everything. There was a very high self-reported speech intelligibility. Then, they were asked to rate their listening effort in all four of the same situations. There was a much larger spread and a lot more variability across the participants' responses for self-reported listening effort. Although they report very high speech intelligibility, they also report varying listening effort.
In summary, research has shown that most of the ecological conditions we find ourselves in on a daily basis are typically positive signal-to-noise ratios (+5 dB or better). Furthermore, we know that the subjective effort varies across those situations, as does the overall sound level. Test subjects reported that they understand most of the speech in those situations, which is not too surprising given the positive SNR. However, although they could understand the speech, they also reported expending quite a bit of listening effort. As we discussed in the beginning of the presentation, the effort may vary, although you have a high speech intelligibility. You might just have to work harder to get that to that speech intelligibility.
Cognitive Measures Beyond Speech Performance Testing
Why do we care so much about these natural listening situations? It ties into the next part about how should we be measuring these cognitive effects. Consider a speech in noise task using the Hearing in Noise Test (HINT). Many bone conduction users have a perfectly healthy inner ear; they have a conductive loss with no sensorineural component (or a minimal sensorineural component). On sentence in noise tests like the HINT, they will likely perform somewhere between -2 to -7 dB SNR. However, in their daily lives, the situations they will encounter will be in the +5 dB SNR or higher range. Why don't we test at +5 dB SNR? Because when the SNR is positive, we can't measure any effects. And, the sensitivity of tests like the HINT are poor when the SNR is very positive. We know many bone conduction users report having difficulty in daily life, but we won't be able to measure any effect on many common speech in noise tests. So, how can we measure that?
SWIR Test
The SWIR (Sentence Final Word Identification and Recall) test was developed by our Eriksholm Research department. The original seven HINT sentences are in Danish (although the language does not matter). The task is to listen to HINT sentences in noise. Before we start the test, we make sure that participants understand at least 95% of the speech, which puts us into this +5 to +15 dB SNR range, where we want to be matching everyday situations. The task is to listen to a sentence, and then repeat the last word of the sentence out loud, for seven sentences in a row. Afterwards, the real task is to see how many of the final words participants can recall (participants were told this up front). The highest possible score is seven; on average, a participant might be able to recall four or five words. In summary, with the SWIR test, the participant has close to 100% speech intelligibility, but much less than 100% recall. This is something we can measure to see the cognitive aspects of hearing.
Working Memory
Many researchers have been looking into working memory. This connects back to our Understanding of Language model, which explains that we can compensate for poor stimuli or speech signal by using our working memory to make sure we understand it. Briefly, you could say the working memory is a cognitive system which has a limited capacity. This capacity is fixed for a given person and does not vary over time, if the person is not very young or old. For each person, the working memory has a fixed capacity and is responsible for temporarily holding information while we make it available for processing to ensure that we understand what is being said. The rest of our working memory we can use for something else. For instance, making sure we store what we hear, in order to remember what we heard.
In Figure 4, we can see what our memory score might look like in different scenarios. The top bar in the figure is when a person is speaking in quiet. The middle bar is the same person in noise. In a noisy situation, we need to spend more of our working memory on processing to make sure we understand the speech, and therefore, we have less working memory remaining to ensure we store it. In a situation with even more background noise (bottom bar), we need to make sure we process speech to understand, and therefore have even less working memory leftover.
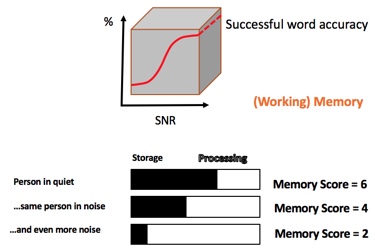
Figure 4. Memory scores in different listening scenarios.
When we develop our hearing aids, we are interested in the affect that our technology can have on cognition and speech intelligibility in noisy situations. As such, we need to be able to measure these cognitive aspects of hearing. We can obtain those measurements in three ways: through brain activity, behavioral responses and physiological correlates.
Brain activity. We can measure cognitive aspects of hearing by looking directly at brain activity. Earlier, I presented some fMRI images where you can see how the brain reacts to understanding speech. We can also use EEG. Another method of looking at brain activity that is gaining more attention in our field is fNIRS. This is an optical imaging technique that measures in a similar way as the fMRI. fNIRS can be used at the same time as you use a bone anchored device. These are ways of looking at how the brain reacts while trying to understand speech.
Behaviroal responses. The second method of measuring the impact that listening effort has on cognitive load is through looking at a person's behavioral responses. When we talked earlier about working memory, we discussed that working memory has a fixed capacity that can be used in different ways. There are a variety of behavioral response tests that require participants to complete dual tasks. They are asked to listen to speech, and also to do something else at the same time (e.g., drawing a figure, completing a dot-to-dot puzzle). By measuring a participant's response time while performing the second task, we can indirectly measure how much working memory the participant has spent on understanding speech.
Physiological correlates. Additionally, we can measure cognitive aspects of hearing by using physiological correlates, such as pupil dilation, skin conduction and stress hormones. For the purposes of today's webinar, I will elaborate only on pupil dilation.
Pupillometry
Pupillometry is the study of changes in the diameter of the pupil as a function of cognitive processing. In this example, the person is given a HINT sentence that they are asked to understand. Once the sentence begins, you can see that while trying to understand the sentence, the participant's pupil size increases (dilates). Once the sentence is done and the task is completed, the pupils will shrink down again.
Research
Lunner, Rudner, Rossencom, Argen, and Ng (2016) conducted a study where the objective of the experiment was to compare direct-drive and skin-drive transmission in users of bone-anchored hearing aids with conductive hearing loss or mixed sensorineural and conductive hearing loss. As you may be aware, when you try to obtain vibrations through the skin, you lose high frequency sounds (anything above 500 Hz will become attenuated by 10-15 dB up in the higher frequencies). The sample group consisted of 16 Ponto Plus Power patients, with conductive and mixed hearing losses, but all within the same fitting range. Ponto Plus Power devices were used, even on the purely conductive losses. They used two devices simultaneously. Each patient was blinded to the condition that was being tested. They also did the individual fittings of the two systems with in situ measurements of both devices, performing the best possible fitting of each using the softband correction. Then, researchers found the signal-to-noise ratio individually, so that participants understood HINT sentences about 95% of the time. On average, they were in the 10 dB range. Furthermore, researchers measured 10 times how much they recalled in this SWIR test. When looking at the results, they found that recall was significantly improved for abutment as compared to a softband fitting. With abutment/direct-drive, they observed a 13% improvement of words correctly recalled from the SWIR test, as compared to a softband/skin drive transmission condition. These findings indicate that spoken word recall can be used to identify benefits from hearing aid signal processing at ecologically valid, positive SNRs where SRTs are insensitive.
Pittman (2008) conducted an experiement a number of years back. The purpose of the study was to examine children's word learning in limited and extended high-frequency bandwidth conditions. Researchers studied how fast children can learn new nonsense words. These conditions represented typical listening environments for children with hearing loss and children with normal hearing, respectively. Although this particular study did not include children with bone anchored devices, the findings are intriguing nonetheless. The subjects included 36 children with normal hearing and 14 children with moderate-to-severe hearing loss. All of the children were between 8 and 10 years of age, and were assigned to either the limited (5 kHz) or the extended (10 kHz) bandwidth conditions. Five nonsense words were paired with 5 novel pictures. Word learning was assessed in a single session, multi-trial, learning paradigm lasting approximately 15 minutes. Learning rate was defined as the number of exposures necessary to achieve 70% correct performance. In this short-term learning paradigm, the children in both groups required three times as many exposures to learn each new word in the limited bandwidth condition (5 kHz) compared to the extended bandwidth condition (10 kHz). These results suggest that children with hearing loss may benefit from extended high-frequency amplification when learning new words and for other long-term auditory processes.
At Osseo in 2017, Andrea Pittman presented preliminary results on a similar, ongoing experiment with bone anchored devices. We'll have full results later on, but her findings suggest that we can measure not only how much children can recall, but also how fast they learn, which is very important for school-aged children.
BrainHearing: Guiding the Products We Bring to the Market
We have seen examples of how we can measure the effect a device has on listening effort and how we understand speech. These results guide the type of products we bring to market. Oticon Medical provides two types of bone conduction devices: those with direct sound transmission, and those that transmit via skin drive. Our direct sound transmission devices have direct contact between the bone and the transducer, because that leads to lower listening effort. Direct sound transmission patients can choose to have an implanted transducer, or a transducer in the processor. With our skin drive devices, there is no direct transducer-bone contact. This is a non-surgical alternative for those who cannot undergo surgery, or for those who are awaiting surgery. The skin drive choices use the transducer with a headband or softband, or have the transducer held in place by an implanted magnet.
In the next section, we will elaborate on devices we develop at Oticon Medical, and why we focus on maximum output as one of the key features of the Ponto 3 portfolio. In addition, we will discuss why all bone-anchored users benefit from a higher maximum output. We will review technical limitations, then look at how all these various parts are related: maximum output, gain, dynamic range and distortion. Finally, we will anticipate how patients will react when you fit them with these devices.
All Bone Anchored Users Benefit from Higher Maximum Output
When patients prioritize their challenges, they rank understanding speech in difficult situations as the highest challenge, followed by unclear sound and distortion of sounds. Historically, with bone anchored systems, the maximum power output is low. If you look at a normal distribution of sound levels, from 0 dB (normal hearing) to 120 to 130 dB (threshold of pain), the loudness discomfort level with a bone anchored device is around 95 dB. Until now, the maximum force output of a bone anchored hearing system has been well below that. It is only with the latest SuperPower generation where we can achieve sufficient output to approach 95 dB.
With a bone anchored device, we need sufficient force to vibrate the skull in order to reach the inner ear, but we also need to keep devices small enough to wear. With the size of bone anchored devices, we do not have to worry about output exceeding a patient's loudness discomfort level, or worse, damaging their hearing. Bone anchored users benefit from a higher maximum output. Why is that? It is because sound environments are dynamic. We discussed how there is a great deal of variation in sound levels in everyday situations, and that these situations also contain relatively high sound levels. Think of a bone anchored device having an input side (the microphone) and an output side (where the signal is transmitted to the user, after the input signal has been amplified). The output signal is, of course, limited by the device's maximum output. In everyday situations, sound levels from very soft to very loud are being sent to the device, amplified, and the signal is reproduced at the output stage. You need a device with a wide dynamic range or sounds will be distorted. This is shown in Figure 5.
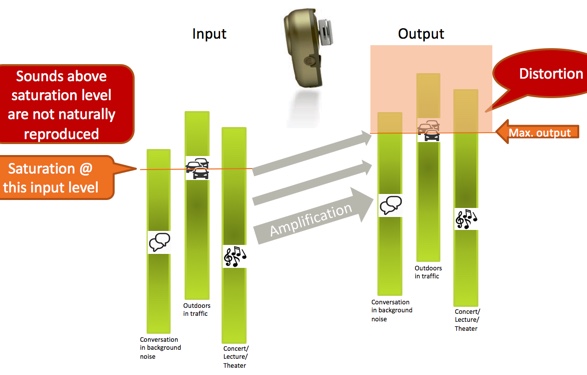
Figure 5. Amplification in three everyday situations.
Three everyday situations are represented by the green vertical bars: conversation in background noise, outdoors in traffic, and a concert/lecture/theater setting. You see these situations have a wide dynamic range (represented by the length of the green bars) as there is a lot of variation in the sound levels within those environments. Let us consider that these situations are being presented to the input of a bone anchored device, and then amplified. Any sound level within those situations that exceed the maximum power output of the device will reach saturation and be distorted; therefore, they will not be represented in the output signal. This is represented by the orange box in Figure 9. Sounds that would fall within that box are saturated and distorted; below the saturation level, the dynamics of the sound environment including speech are correctly reproduced.
The Ponto 3 SuperPower has 10 dB higher maximum output (maximum force output level, MFO) and is the strongest abutment level sound processor meant for a 45 dB HL fitting range. The higher output means a larger proportion of the natural dynamic variations in everyday situations will be maintained. This is shown in Figure 6. You'll see that with a higher output, more of the dynamic range of everyday situations (represented by the green bars) are correctly reproduced. When higher gain is used in a device, saturation is reached quickly, so this is very important.
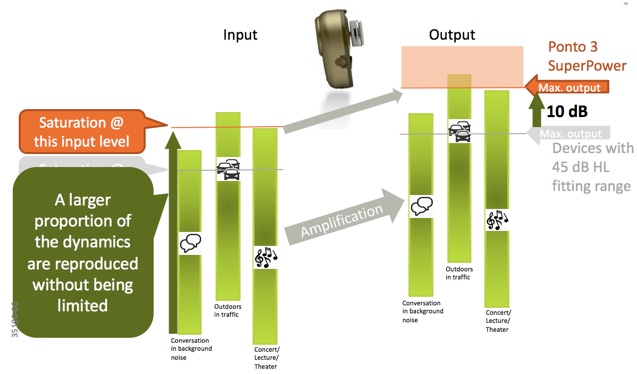
Figure 6. Ponto3 SuperPower provides more dynamic range in everyday situations.
Who can benefit from a Ponto 3 SuperPower? Everyone using a bone anchored system deserves the best sound quality. Ponto 3 SuperPower is beneficial for conductive hearing losses, mixed hearing losses, single-sided deafness patients and for softband fittings. For patients with conductive or mixed hearing loss, the higher MFO of Ponto 3 SuperPower device provides an increased dynamic range so it correctly reproduces more sounds without distortion. The benefit is natural hearing and a better sound quality. With a Softband or a headband fitting, Ponto 3 SuperPower will provide higher gain to account for skin attenuation to make the signal audible. The SuperPower device will enlarge the dynamic range so that the patient can listen and hear naturally without distortion. Patients with single-sided deafness (SSD) will experience a superior loudness match between their two ears when using a Ponto 3 SuperPower device. As you can imagine, with a normal hearing ear on one side, and a device on the other ear that saturates at high levels or a moderate-high level, they have a mismatch of sounds coming from the two sides. With Ponto 3 SuperPower, patients with SSD report an improved spatial awareness because the loudness of the signal coming from the device now matches the loudness from the normal hearing ear.
Will I Be Overfitting Patients with a SuperPower Device?
With hearing aids, we may associate the term "SuperPower" with devices that have high internal noise floors and only appropriate for those with the significant degrees of hearing loss. The question we often hear is, "Will I be overfitting patients with Ponto 3 SuperPower?" The answer is no; it is virtually impossible to overfit a bone anchored hearing device. The maximum output of even the SuperPower device will be lower than the loudness discomfort level. With bone anchored, although we call it SuperPower, there is no risk of overfitting the bone anchored to the user. It is important to note that the "Be Careful! High Power Instruments" warning that appears in Genie when fitting AC power hearing aids does not apply to bone anchored devices. You cannot hurt anyone's hearing using a BAHA SuperPower device.
The other question is whether you would only use a SuperPower hearing aid for someone with a signigicant loss who needs to be prescribed with high gain. With the bone anchored device and with our Ponto 3 family, the gain is prescribed by taking the patient's hearing loss into account. For a given hearing loss, the gain will be the same for a SuperPower device as for a Ponto 3 regular 45 dB device. The gain will be prescribed the same way with a SuperPower as with a normal device. In that sense, there is no risk for the patient. Additionally, the volume control can only be increased in increments of 10 dB, so there is no risk of over-amplification. Sometimes, we receive questions about noise floor and you don't need to worry about that either for bone anchored devices. The take away here is that the bone anchored SuperPower device needs to be seen as something different than a hearing aid SuperPower device.
What do patients say? In a study by Bosman, Kruyt, Mylanus, Hol, and Snik (2017), a group of patients tested a Ponto 3 SuperPower device, as well as a Ponto Pro Power device. In an APHAB questionnaire, they reported the same degree of aversiveness to loud sounds with the Ponto 3 SuperPower as compared to the Ponto Pro Power. This study also looked at loudness discomfort levels, which were estimated to be in the same range as we have seen previously in literature (around 90 dB for bone anchored). Again, this is about what we can reach with the SuperPower device. Another important element of patient experience is to find out what they have previously worn. For example, you may have a patient who is accustomed to a device for a 45-dB hearing loss. Figure 7 shows an example of the output curves of a patient wearing a Ponto 3 device. At 70 dB, the device is already in saturation. That means that anything beyond 70 dB (which occurs all the time in natural situations), sounds are distorted and perceived as loud sounds.
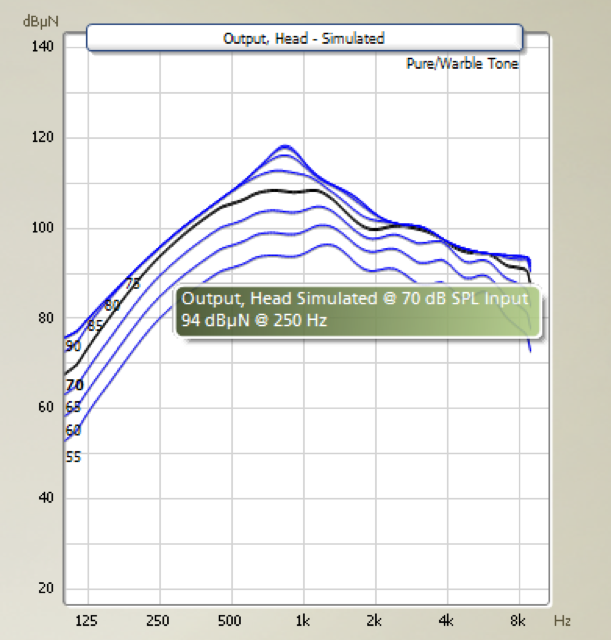
Figure 7. Maximum force output, Ponto 3.
Let us look at the output curves for the same user fitted with a Ponto 3 SuperPower (Figure 8). Again, we have prescribed exactly the same gain for this user, independent of device.
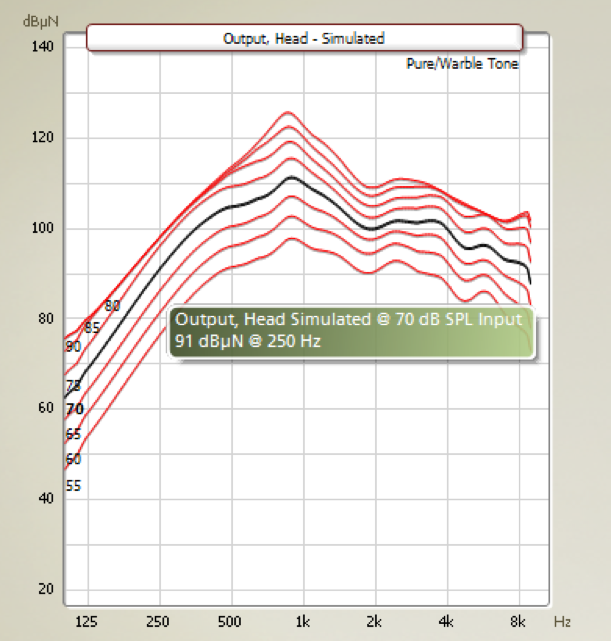
Figure 8. Maximum force output, Ponto 3 SuperPower.
Highlighted by the black curve, you can see the simulated output at the 70-dB input, which is in the middle of the dynamic range of this device. At this level and beyond, the patient experiences much less saturation, which means that there is less sound distortion. In the Bosman study that we cited earlier, patients using the Ponto 3 SuperPower reported that sounds were balanced, quieter, natural and calm. One patient reported that he was less startled by sudden and loud sounds. The higher maximum output actually makes the device sound calmer, which is related to the fact that we can handle larger dynamic ranges.
Should This Influence How We Counsel Patients?
Given the limitations of bone anchored devices, Oticon Medical's recommendation is that all users would benefit from a SuperPower device. Of course, no patient would ever ask for a SuperPower device. That is not how it works. Naturally, patients will immediately be interested in the features that are tangible: the way the processor looks, size, color, its ease of handling and whether it has wireless capability. From a professional point of view, it is important that we include non-tangible aspects when counseling patients (e.g., sound quality, speech understanding, reliability), so that in the end, patients can make an informed choice. Let your patients experience the difference. We are sure that they will come back and tell you that they do hear a difference. However, It is important to remember that they may not hear a difference one-on-one in a quiet room. The benefits of a SuperPower device are related to dynamic situations with varying sound levels, including high levels. When patients try SuperPower devices, ensure that they use them in different settings, to achieve an accurate representation of the situations they encounter in their everyday lives. We have developed a test guide with a notes section to help patients collect their experiences while testing the sound processor in different dynamic listening situations (e.g., at a cafe, outdoors, in a hospital, etc.). We also have materials geared toward patients who want to try a softband before they make their final decision.
Conclusion
At Oticon Medical, we believe that the Ponto 3 SuperPower is the device that fits everyone. With our higher maximum output, users experience less sound distortion, as well as a larger dynamic range of naturally reproduced listening environments. The Ponto 3 SuperPower has the highest MFO in any abutment level device, although It is below the patient's loudness discomfort level. With BrainHearing, we deliver technology for hearing implant patients that improves speech recognition, reduces listening effort and increases recall capabilities.
References
Bosman, A., Kruyt, I., Mylanus, E., Hol, M., & Snik, A. (2017). On the Evaluation of a SuperPower Sound Processor for Bone-Anchored Hearing. Clinical Otolaryngology, 10(1111).
Grossman, M., Cooke, A., DeVita, C., Chen, W., Moore, P., Detre, J., Alsop, D., & Gee, J. (2002). Sentence processing strategies in healthy seniors with poor comprehension: an fMRI study. Brain Lang., 80, 296–313.
Lazard, D., & Giraud, A. (2017). Faster phonological processing and right occipito-temporal coupling in deaf adults signal poor cochlear implant outcome. Nature Communications, 8.
Liberman, C., Liberman, L., & Mainson, S. (2015). Chronic Conductive Hearing Loss Leads to Cochlear Degeneration. PLOS ONE, 10(11).
Lunner, T., Rudner, M., Rossencom, T., Argen, J., & Ng., E.H. (2016). Using speech recall in hearing aid fitting and outcome evaluation under ecological test conditions. Ear & Haring, 37(Suppl 1), 145S-54S.
Peelle, J., Troiani, V., Grossman, M., & Wingfield, A. (2011). Hearing loss in older adults affects neural systems supporting speech comprehension. J. Neurosci., 31(35), 12638-43.
Pittman, A. (2008). Short-term word learning rate in children with normal hearing and children with hearing loss in limited and extended high-frequency bandwidths. J. Speech Lang. Hear. Res., 51(3), 785-797.
Reinfeldt, S., Ostli, P., Hakansson, B., Taghavi, H., Eeg-Olofsson, M., & Stalfors, J. (2015). Study of the feasible size of a bone conduction implant transducer in the temporal bone. Oto. Neurotol., 34(4), 631-37.
Rönnberg, J., Lunner, T., Zekveld, A. A., Sörqvist, P., Danielsson, H., Lyxell, B., et al. (2013). The ease of language understanding (ELU) model: theoretical, empirical, and clinical advances. Front. Syst. Neurosci., 7(31).
Rönnberg, J., Rudner, M., & Lunner, T. (2011). Cognitive hearing science: the legacy of Stuart Gatehouse. Trends Amplif., 15(3), 140-8.
Smeds, K., Wolters, F., & Rung, M. (2015). Estimation of signal-to-noise ratios in realistic sound scenarios. J. Am. Acad. Audiol., 26(2), 183-96.
Yang, Y., Marslen-Wilson, W., & Bozic, M. (2017). Syntactic complexity and frequency in the neurocognitive language system. Journal of Cognitive Neuroscience, 29(9), 1605-20.
Citation
Holmberg, M. (2018, February). BrainHearing and bone anchored devices: Why more output matters to all users. AudiologyOnline, Article 21522. Retrieved from www.audiologyonline.com

