
Learning Outcomes
After this course, participants will be able to:
- Recognize that different signal processing approaches in high-end hearing aids attack the speech in noise problem in different ways.
- Develop the ability to glean information about dynamic device performance by looking at various advance visual representations (such as spectrographs, waveforms, etc.).
- Recognize that some systems can meet certain performance criteria (such as reduction of noises arising from behind) at the expense of other criteria (such as maintenance of a full gain response).
Introduction and Overview
My name is Don Schum, and I'm the Vice President of Audiology at Oticon. Throughout this presentation, we will discuss how our most important signal processing technology, OpenSound Navigator (OSN), works in complex environments. We developed OpenSound Navigator to assist patients with hearing loss to communicate more effectively than they could with traditional amplification, especially in more challenging environments, and do so without creating an unnatural listening experience for them. This technology has been available in our top of the line products (Opn, and now Opn S) for over three years now. During that three-year timeframe, we were able to obtain more knowledge about how well patients perform with OpenSound Navigator, and about how this technology works. Today, we will take a deeper dive into what we know about the function of this important technology.
A Philosophical Look at Listening Environments
Before we dive into the specifics of signal processing, I want to step back, take a philosophical look at listening environments. Throughout the day, all of us experience a lot of different listening environments, whether we have normal hearing or a hearing impairment. A listening environment isn't simply a background. A listening environment involves more than the sounds that are around you. The listening environment tends to link you with a moment in a place and time. There is a whole area of architectural acoustics called soundscapes. The idea with soundscapes is that a situation is supposed to sound a certain way. A busy restaurant at lunchtime should have a different sound than an elegant fine dining establishment. A Starbucks at 7:45 in the morning sounds different than that same Starbucks at 2:30 in the afternoon. Different places based on what you expect should sound a certain way.
In the field of audiology, we deal with sound, and we deal with people who have trouble perceiving sounds. As such, it's crucial not to become too unidimensional about the way we think about sounds. We need to keep in mind what sounds bring to individuals. As we dive deeper into the topic of how humans perceive sounds, we will examine two projects that came out of Sweden. One is from Axelsson, Nilsson & Berglund; the other is from Skagerstrand, Stenfelt, Arlinger & Wikstrom.
Axelsson, Nilsson & Berglund
The first group of researchers examined the way people with normal hearing perceive different sounds in different environments. They did a variety of multidimensional scaling analyses on the way humans rate different sounds. They came up with two dominant dimensions in the way that sounds can be classified. As shown in Figure 1, the dimension represented on the horizontal axis includes sounds that can be described on a continuum from unpleasant to pleasant. The second dominant dimension, as shown on the vertical axis of Figure 1, includes sounds that can be considered eventful versus uneventful. In other words, in an environment, there may be a lot of sounds occurring, or it may be a non-eventful situation.
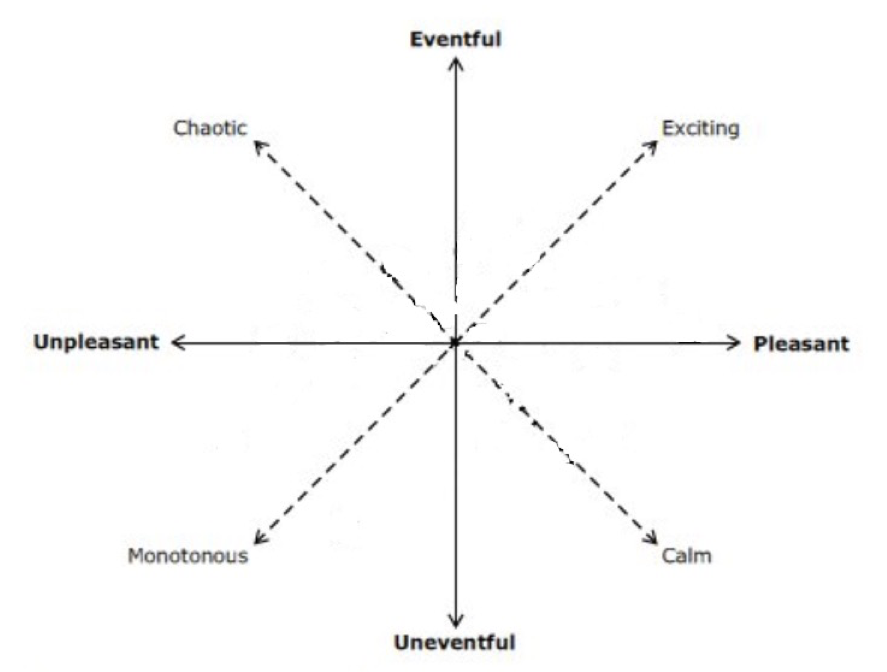
Figure 1. Dimensions of sound classification.
On the diagonal quadrants, they labeled four different types of environments you can find yourself in. First, if you are in a situation that's eventful and pleasant, it can feel exciting. In other words, if there are a lot of people around and there seems to be a certain energy in the crowd, that's exciting. Imagine if you went to a night club on a Friday night to go dancing and you get there, and it's dull. That's not what you would expect. You want it to be exciting. You expect to hear sounds. You expect to hear people, and you expect a certain excitement.
Next, if you find yourself in a situation where you hear sounds that are pleasant but uneventful, that situation is considered to be calm. Think of a Zen garden or a quiet conversation with a friend. Those are instances that would be classified as pleasant but uneventful.
You may find yourself in a situation that could be classified as eventful and unpleasant, where there are a lot of sounds in the environment that are not necessarily positive sounds to listen to. That environment is going to evoke feelings of chaos (e.g., construction site, accident sirens).
Finally, there are settings where sounds can be classified as unpleasant and uneventful. That setting would be considered monotonous. For example, there may be a piece of machinery that's droning on and on. It is loud enough that you can't ignore it, but it's so ongoing that it's just monotonous.
In this study, they played a variety of different sounds that were classified one of three ways: as human sounds (primarily speech), technology sounds or nature sounds. They plotted the sounds on the classification quadrants that they created (Figure 2). Human or speech sounds, indicated by the gray boxes, are almost exclusively on the pleasant side of the continuum. In general, normal-hearing individuals almost always consider human speech to be pleasant sounds that are worth listening to, unless the environment is an eventful unpleasant situation (e.g., a chaotic environment where there are a lot of people talking over each other at the same time). Technology sounds are represented by the gray circles. These would include the sounds of such things as machinery or traffic. Those sounds are almost always considered to be unpleasant. They could either be unpleasant and monotonous or unpleasant and chaotic, but they tend to be rated as unpleasant, as kind of unnecessary and not necessarily something that you desire. Nature sounds, represented by the black outlined squares, were mainly classified as being pleasant, with a few situations landing in the unpleasant/eventful quadrant.
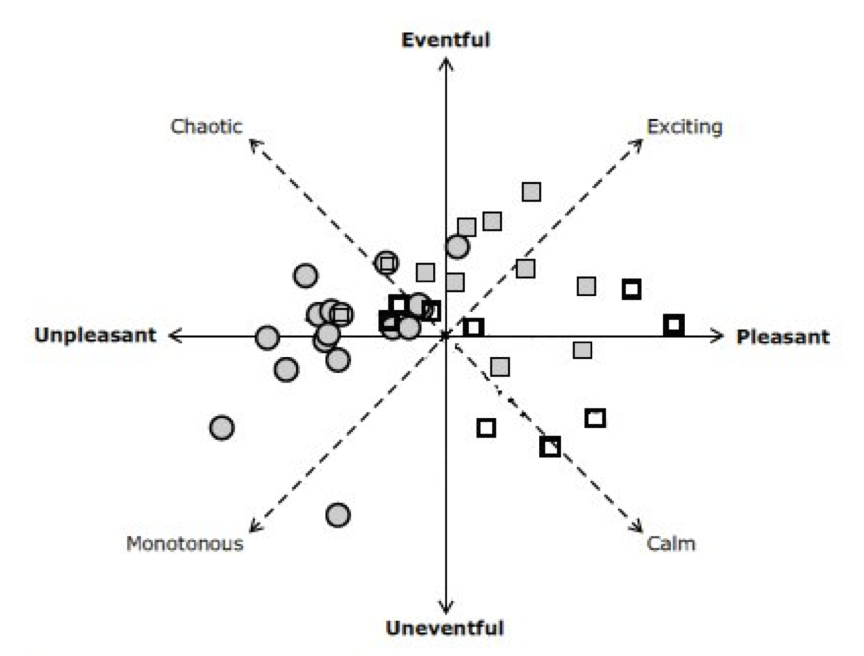
Figure 2. Classification of sounds.
Skagerstrand, Stenfelt, Arlinger & Wikstrom
When you think about the effect of hearing loss, you start to consider how people with hearing loss relate to speech. The second project we will examine collected data on what individuals with hearing loss considered to be annoying or unpleasant sounds to listen to. This is from a different group of Swedish researchers, Stig Arglinger, and his group at Linkoping University. They evaluated the sounds that are rated as most annoying by people who have a hearing impairment.
| Stated annoying sound or sound source | Description |
| Verbal human sounds | Sounds produced by people, verbal. An example of these sounds is murmuring |
| TV/Radio | Sounds emitted from the loudspeakers of TV and/or radio |
| Vehicles | Sounds produced by vehicles with engines; cars, trains, motorcycles, etc. |
| Machine tools | Sounds produced by power tools, such as a power saw or drilling machine |
| Household appliance | Sounds produced by ordinary household appliances, such as a washing machine, vacuum cleaner or electric mixer |
Interestingly, the top two types of sounds that are rated as annoying by people with hearing impairment are verbal human sounds, as well as the TV or radio (which often contain speech sounds). This finding is in direct contrast to people with normal hearing, who generally consider speech to be a pleasant sound. In the big picture, it's a shame that speech - which connects us with other humans - is perceived negatively in the presence of hearing loss. In addition, technology sounds and similar background noises that normal hearing people perceive as negative are going to become even more negative in the presence of hearing loss.
This brings to mind an older study that was completed at the end of World War II. When the soldiers and seamen were coming back from World War II, one of the things that was noted was that there was a lot of depression and even suicide by these returning veterans who had lost their hearing. Researchers enlisted the help of a psychiatrist named Ramsdell, working out of the Deshon Army Hospital in Pennsylvania. They asked him to do an analysis and find out why the loss of hearing would be so severe as to lead to depression and suicide.
Ramsdell conducted an analysis which was published as a chapter in one of the original important audiology textbooks, the Davis and Silverman textbook. In his chapter, Ramsdell talked about the different purposes or levels of hearing. The first level of hearing is the Warning level. These are sounds that keep us alive, such as being able to hear the siren of a blaring fire truck racing by, or the honk of a car horn. Warning sounds are there for our preservation. The second purpose of sound would be the Social level. That is where you get information from sound. For humans, probably the most common source of information from sounds is the speech of other humans. Speech is the way we communicate with each other to try to get information across. The third level of hearing is known as the Primitive level of hearing. Ramsdell described the primitive level of hearing as a connection to a place and a connection to your environment. It is this level of hearing that he believed was the cause of depression and suicide in veterans with hearing loss. When you lose hearing, especially suddenly like these combat war veterans did, that disengages the person from the rest of society and the rest of life. Not surprisingly, this leads to depression and sadly, suicide.
OpenSound Navigator: Design Purpose
The reason we created OpenSound Navigator was to allow individuals with hearing loss to be able to continue to engage as much as they want to in the types of social situations that they find positive. We don't feel that speech communication should solely be considered a one-to-one situation. There are plenty of opportunities for individuals with hearing impairment to have the opportunity to engage in conversations with more than one person at a time, in group situations. Even in conversations with one person at a time, it shouldn't feel like you're in a communication bubble where that's the only thing that you hear. Oftentimes, we are in situations and environments where the full sound experience is important. Simply put, the design purpose of OpenSound Navigator is to improve speech understanding performance in complex environments without unduly sacrificing a natural listening experience.
A variety of technologies have been developed over the years. Traditional directionality and noise reduction essentially plateaued about 10 years ago or so. The signal processing routines that were incorporated in traditional directionality and noise reduction didn't seem to be evolving much beyond the principles that were put in place 15 or 20 years ago. The principles of adaptive automatic directionality and also automatic noise reduction in hearing aids (modulation-based long-term noise reduction) entered the marketplace about 15 or 20 years ago. These principles were refined but then remained static for a number of years. As such, patients were still running into some amount of difficulty.
One reaction that came out of the hearing aid industry was the idea of creating beamforming. Beamforming, as you know, is a technology that became available once we were able to achieve wireless connectivity between the two hearing aids. With the four microphones available, we were able to create a much narrower listening channel for the patient. That was considered the next step in environmental sound processing for patients with hearing impairment. Beamforming was effective in that if you were listening to one person directly in front of you and they were not too far away from you (within a meter or two), beamforming can create this narrow channel to allow you to hear.
The problem with beamforming is that you were creating a "hearing isolation tank" for the listener, rather than focusing on a fully natural listening experience. Essentially, the beamforming mentality was that since sensorineural hearing loss is such a difficult problem to solve, the only way we can solve it is to dramatically restrict what the patient has to listen to, and that's the best we can do. However, over time, we felt that that wasn't the best we could do. We believed that we could improve patient's performance in complex environments without putting this unnatural restriction on being able to hear more of the sounds in the environment. That's why we created OpenSound Navigator.
With OpenSound Navigator, we are proud of the fact that, via high-quality research using independent sources, we've been able to close the gap between hearing impairment and normal hearing. In the complex environments under which we test, we've been able to demonstrate that individuals with sensorineural hearing loss using OpenSound Navigator can perform on par with normal hearing individuals in similar situations. We are not claiming that we are able to restore hearing to normal. There is still a disordered hearing system. However, under the complex listening conditions in which we have conducted testing, we have been able to show that hearing impaired individuals with OpenSound Navigator can perform at similar levels to people with normal hearing. We consider it to be a great sign of success that OpenSound Navigator allowed us to achieve those results.
Ohlenforst et al., 2017
At this point, I'd like to share some details of the work that was done. We teamed up with a research group out of the Netherlands (Ohlenforst et al., 2017). They conducted a study using a group of patients with hearing impairment. These patients wore our Opn product, and they were tested under a variety of conditions with OpenSound Navigator turned off and OpenSound Navigator turned on. First, we tested subjects on speech understanding performance in noise at a variety of different signal-to-noise ratios. In addition, we measured their pupil dilation during testing, as decades of research has shown that the size of the pupil is a reflection of the amount of cognitive effort put forth during a task. Patients with hearing loss often talk about how hard it is to live with a hearing loss, and how much effort they have to put into the task. As such, the way we go about testing is to take this BrainHearing approach to find out what we can learn, not just about how well patients can hear and repeat words, but how hard they have to work during these listening tasks.
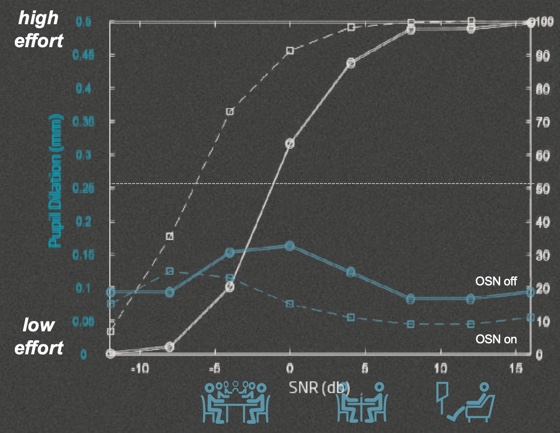
Figure 3. Pupil dilation with OSN off vs. on.
In Figure 3, with OpenSound Navigator off (solid white line), you see the typical performance-intensity function that you would expect for speech material in a background of noise. Once we turn OpenSound Navigator on (dotted white line), the signal-to-noise ratio at which subjects could perform the task shifted to the left, on average, about 5 dB across different testing levels. Essentially, what we're seeing is across the main range of the performance intensity function is that we're able to improve the ability for subjects to operate in noise by about 5 dB, which is a sizeable improvement.
On the left-hand Y-axis is a measure of pupil dilation. With OpenSound Navigator off (solid green line), when the signal-to-noise ratio is very good, the peak pupil dilation while listening and repeating sentences is at a certain baseline level. As the signal-to-noise ratio gets poorer, the peak pupil dilation starts to increase. In other words, as the signal-to-noise ratio gets poorer and poorer, the patient has to work harder at a cognitive level to understand speech. Interestingly, when the signal-to-noise ratio gets very poor, the peak pupil dilation drops again. You might be a little bit surprised by that but think about what happens when you're in a challenging listening situation. Even with normal hearing, there's a point at which you simply give up. You recognize that you're not going to understand anything and so you just stop trying. That's what you see with the peak pupil dilation. The pupil dilation data is an interesting reveal about the way people manage their cognitive resources. The amount of cognitive effort put into a task is primarily under the control of the listener. You'll put in as much effort as you need to, as long as you're getting success. If you get to the point where you're no longer getting success, then you stop trying.
Now, if you take a look at look at the data with OpenSound Navigator on (dotted green line), you will notice the same sort of pattern but with overall lower peak pupil dilations. In general, OpenSound Navigator makes it easier to understand speech. It's important to notice that there is still a peak in the function, but that peak in the function is now moved down a good 5 dB or even more with OpenSound Navigator on, which is consistent with the data we saw with the speech understanding also on the graph. We can shift the response down to about 5 dB or more in poorer situations and allow the patient to still operate well. This data indicates that with OpenSound Navigator on, patients are willing to invest the cognitive effort to hear and understand in situations that are poorer than if they just had basic, non-linear amplification available to them.
Figure 4 demonstrates what we mean when we say that the hearing impaired subjects understood speech "on par" with normal hearing subjects. This study was redone, but this time included normal-hearing individuals. The lower panel in Figure 4 shows the speech understanding scores and word recognition scores. The upper panel shows the pupil dilation scores. The normal hearing subjects are shown in green.
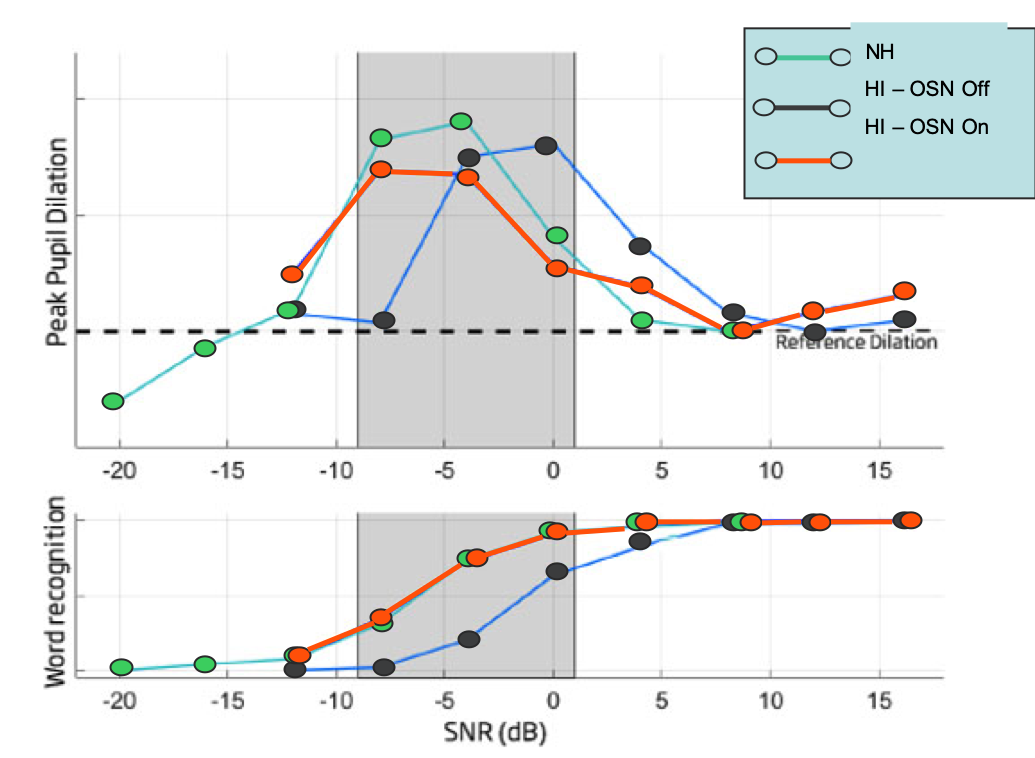
Figure 4. Score comparison: normal hearing vs. hearing impaired with OSN turned on.
First of all, let's check the speech understanding scores. Notice that the speech understanding scores for normal-hearing individuals are superimposed at the same points in the function as individuals with hearing impairment with OpenSound Navigator turned on. Next, if you take a look at the pupil dilation measures, you'll notice once again that the people with normal hearing show a function that's very similar to those with hearing impairment but with OpenSound Navigator turned on. This data is intriguing to see the positive impact that OpenSound Navigator can have on a hearing impaired patient, compared to normal hearing individuals.
How Does it Work?
How does it work? Figure 5 shows the basic block diagram of OpenSound Navigator.
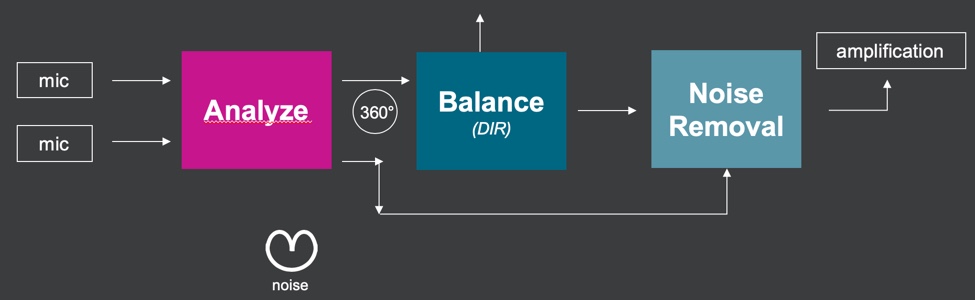
Figure 5. Basic block diagram of OpenSound Navigator.
There are three very important details that set apart the design of OpenSound Navigator from more traditional directionality and more traditional noise reduction systems.
- Analysis phase
- Noise removal phase receives information from the analysis phase
- Update speed
Analysis Phase
The first technical difference is this analysis block. What ends up happening in the analysis block is that we take in a lot of information about the environment in a unique way before we allow directionality or noise removal to do anything to the signal. This is very unique compared to more traditional systems. In most traditional systems, you'd go right from the microphone input directly into the directionality, and then directionality would do whatever directionality is going to do and hand over whatever's left as signal to the noise removal system. Once the noise removal system played its part, the signal would go on to the non-linear compressor. That's the way most modern high-end hearing aids are designed. What they were missing is this analysis block.
The unique thing about the analysis block is that we are evaluating the environment using the power of two microphones to take a look at the environment using both a 360-degree or an omnidirectional look at the environment, as well as a backwards-facing look at the environment. In other words, we use the directional microphones to create a backwards facing polar plot. Part of the analysis is to compare the noise in the general environment with what's happening directly behind the patient. With a good amount of signal massaging and signal processing laid on top of these analyses, that allows both the directionality function and the noise reduction function to be much more targeted in terms of how it attacks the environment.
Noise Removal Phase
The second unique aspect about the way OpenSound Navigator is designed is that the noise removal section gets location information from the analysis block. In most traditional designs, the first thing that happens is directionality. After directionality has done whatever it can to clean up the signal, it hands over that signal to noise removal, but there's no directional information left over. The noise reduction in traditional hearing aids just has to work on that signal without any knowledge about where those sounds came from.
With OpenSound Navigator, we route information that we glean in this analysis function by comparing the 360 degree look at the environment with this backwards facing look at the environment to tell the noise removal system about the location of sounds, as well as which sounds are more likely to be speech-like and which are less likely to be speech-like. One of the reasons why our noise removal system is more effective than traditional systems in the marketplace (including traditional systems that we've used in the past) is that it's spatially aware. In other words, it knows more about the environment than traditional noise removal systems. During the analysis function, we're capturing a lot of information. We capture the frequency (because we're doing 16 channels of analysis), the level at which sounds are occurring, the location from which sounds are coming, and an analysis of whether sounds contain speech or non-speech information. That analysis block is feeding forward a lot of information to both the directionality and the noise removal sections in order for them to do their job.
Update Speed
The third important difference between OpenSound Navigator and traditional noise reduction and directionality systems in the marketplace is the update speed at which we operate. When we created OpenSound Navigator, we created it on a new platform back in 2016 called the Velox platform. More recently, we have updated that platform, and now we're on the Velox S platform. When we released on the Velox platform, we massively increased the processing resources available on that platform. Because we have those processing resources, we are able to implement OpenSound Navigator. One of the most important aspects to make OpenSound Navigator as effective as it has been proven to be is the ability to work at a very fast pace. The update speeds on OpenSound Navigator are 100 times per second (updates every 10 milliseconds). The update speeds on traditional noise reduction and directionality are typically measured in seconds. Oftentimes, you can see update speeds on the order of three seconds, and even five or 10 seconds or longer. This difference in pure horsepower at which this system is running is a big part of what drives the success of OpenSound Navigator.
OpenSound Navigator: Design Differences
In addition to the extremely fast processing speed, there are a few other important design-specific things about OpenSound Navigator. There are clear technical differences between the way OpenSound Navigator was designed and works and the way traditional noise reduction and directionality works. Let's compare OpenSound Navigator to the two other options that are available in the marketplace.
OSN vs. Traditional Directionality and Noise Reduction
First, let's compare OpenSound Navigator with traditional directionality and noise reduction. The design of OpenSound Navigator is unique in that it has an analysis phase that occurs before anything else is happening in the product. In addition, the noise removal part of the system is spatially aware, meaning that we are given information about not only whether a signal is a speech or a non-speech signal, but also where that sound is coming from. That allows our noise reduction system to be much more specific about the sounds that it attacks. Furthermore, the criteria for changes in the noise reduction system are different. We use a different type of voice activity detector, which is different than the traditional modulation approaches that are used in more long-term based noise reduction systems in the marketplace. Finally, the big thing is the update speed. We can update 100 times per second, which is far beyond what you can do with traditional systems.
OSN vs. Beamforming
When we compare OSN to beamforming, again we have the analysis phase and the update speed. But the thing that really sets OSN apart from beamforming is this idea that we will protect clearly defined speech sources, even when they're to the sides, and, to some degree, when they're at the back. There is a directionality function in OpenSound Navigator. We don't just let every sound into the hearing aid. By being able to differentiate between speech sources and non-speech sources, we can target non-speech sources more aggressively than we attack speech sources. We tend to de-emphasize speech sources to some degree coming from the back to a lesser degree from the sides, but we leave the front half of the listening field wide open for any speech sources that happen to be there. We wanted to get to a point where we could improve the patient's performance in complex environments but without creating a narrow listening field or an unnatural listening experience.
KEMAR Recordings Under Different Conditions
To show some of the differences between how these high-end systems work, we completed a variety of different recordings using KEMAR with different high-end products available in the marketplace. The products we used were:
- Opn 1 (our highest tier product)
- A product with an automatic beamformer
- Two products with more traditional directionality and noise reduction
Note: These recordings were done right before we released Opn S 1, but the basic function of OpenSound Navigator hasn't changed between Opn and Opn S. There are some important differences that we made with Open S that I'll talk about in a few minutes, but the basic function of OpenSound Navigator remained the same.
Most of the recordings were done using speech in speech-shaped noise (SSN). In some cases, we used babble, but for the most part, we used speech-shaped noise because it's visually easier to discern in these recordings when noise versus speech is present. We did most of the recordings at a +5 dB SNR, which is a pretty challenging SNR for patients with sensorineural hearing loss. In essence, what we're doing is a technical analysis of the effect of the signal processing on the signal-to-noise ratio. For the purpose of this talk, it's mostly just visual analysis of those waveforms.
Condition 1: Speech from the Front
For the first set of recordings, the audiogram that we used was that of a flat moderate hearing loss, to make sure that we were getting a broadband look at the way the products would respond to the presence of hearing loss across frequency ranges. The first recording could essentially be considered a calibration-type recording. In this recording, we have speech coming from in front of the listener. In all these recordings, the hearing aid was in KEMAR's left ear. That will be important a little bit later when we talk about some of the asymmetrical situations that we were testing under.
Figure 6 shows the long-term average response of the different hearing aids when we tested using speech. Notice that all the hearing aids have a similar response at above 2000 Hz. That's important because once you get above 1500 to 2000 Hz, that's where you're talking about the highest concentration of speech information. Everyone was matched pretty well out there. The different products perform a little bit differently in the mid frequencies from about 500 to about 1500 Hz. There is some variation in the way they respond to sound, and that's more the philosophy of the hearing aids that were being used and tested under this environment. We didn't see these as major differences because those were normal variations that you would expect. However, for the purposes of improving the signal-to-noise ratio, we were interested in the high frequencies and all the products are doing pretty much the same thing out in the higher frequencies in terms of long-term bandwidth.
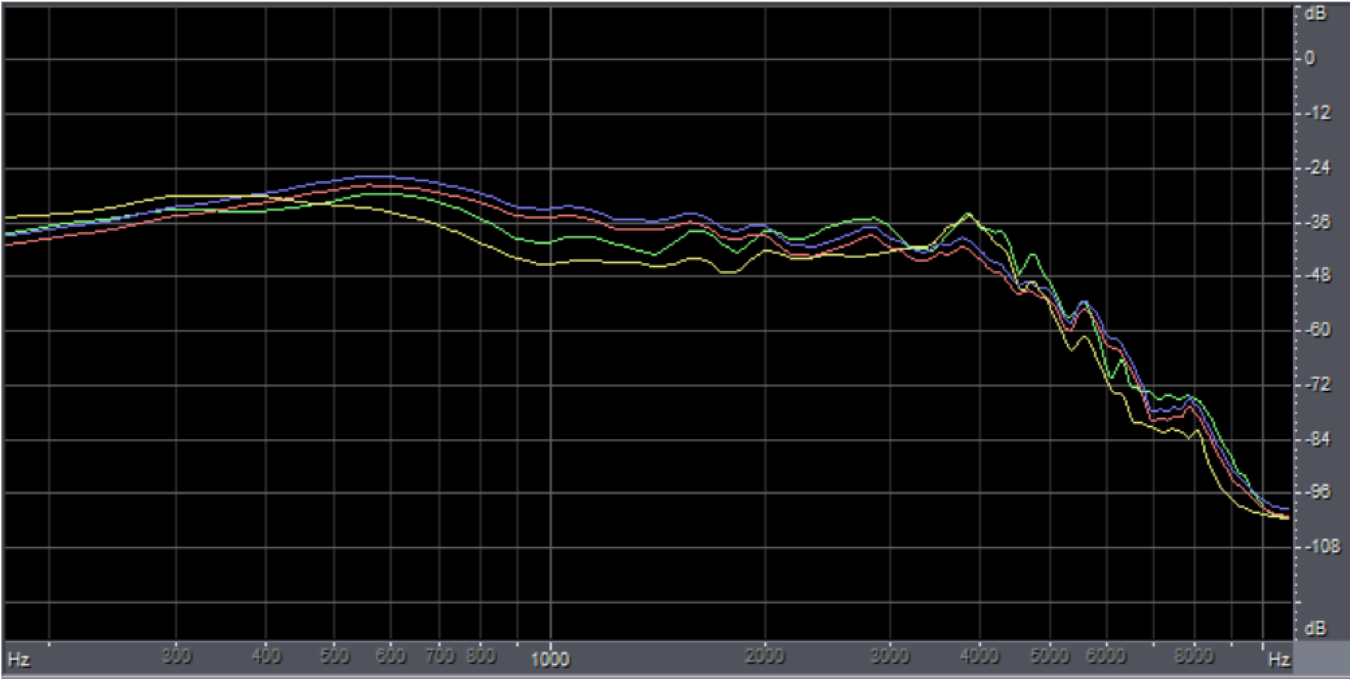
Figure 6. Long-term average response under condition 1: speech from the front.
Figure 7 illustrates the way that we were looking at the output. The top panel is the unaided signal. It starts with speech-shaped noise only going into the hearing aid, and you can see it's nice and stable. Then we start on the speech signal, which has three parts over a 35-second interval. In the first eight or nine seconds, there is only one talker. The middle section adds a second talker. The third section is both people talking at the same time, which is why you see more of a spike pattern or a boost in the overall level. The most important part I want you to notice is how the products respond once the signal processing is engaged.
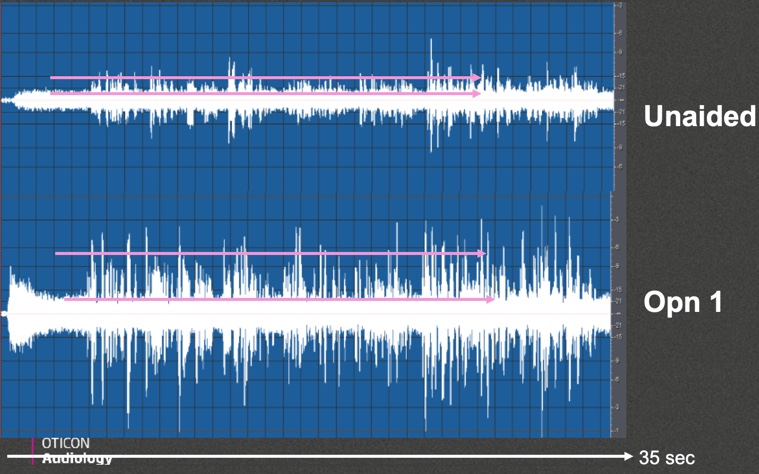
Figure 7. Condition 1 output analysis, unaided vs. Opn 1.
The bottom panel of Figure 7 shows the output of Opn 1 under the first condition within the same 35-second window. In the first couple of seconds with no speech present, the hearing aid will do something with the noise, but since there's no speech present, there isn't a sense of urgency for the signal processing to control that. Notice that within the first few seconds it's settling down into a nice stable level.
The distance between the pink lines represent the improvement in the signal-to-noise ratio. In the top panel in the unaided condition, there is about a 5 dB difference between the pink lines based on the scale that was being used (we set up a 5 dB SNR as the input level). In the bottom panel looking at the output level of Opn, you see that the SNR improves by about 5 dB, resulting in a 10 dB difference between the ongoing background noise and the typical peaks of the speech signal. Under that condition, you can see the effect of OpenSound Navigator in that environment.
Condition 2: Speech from the Front and Side
We set up this condition to try to show the difference between what OpenSound Navigator would do versus what a beamforming product would do under an asymmetrical listening condition. In this condition, we had speech coming from in front and also speech coming from 90 degrees off to the side. Similar to Condition 1, the first section of speech will include only one talker, the second section of speech will add a second talker, and the third section will have both of these talkers at the same time. That was recorded with speech-shaped noise coming from behind and speech-shaped noise coming 90 degrees off to the other side.
Figure 8 shows the output for this condition. The top panel is the unaided signal, and the bottom panel is the output with Opn. When speech is coming from in front, you can see an improvement of about 5 dB in the signal-to-noise ratio, which we would expect. When speech is coming from the side, you still see an improvement in the signal-to-noise ratio, though not as dramatically because we don't put full emphasis on speech coming from 90 degrees on the side. We de-emphasize it a little bit to try to put a more focus on the front half of the listening field. But it still comes through and improves the signal-to-noise ratio, and we definitely don't bury speech when it's coming from the side. Finally, you see what happens when you have speech coming from both the front and the side.
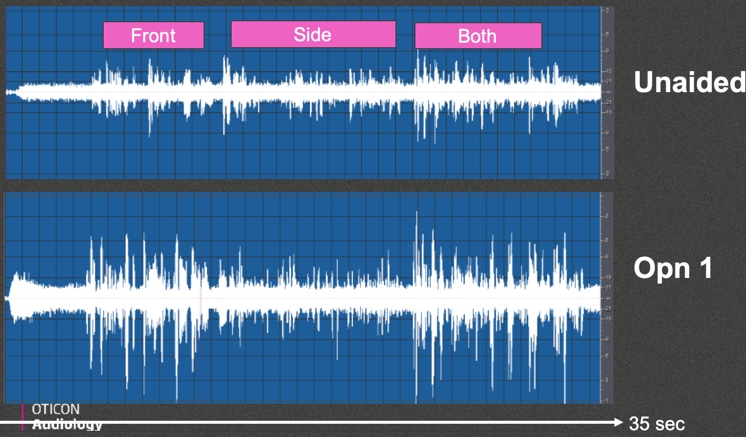
Figure 8. Condition 2 output analysis, unaided vs. Opn 1.
In contrast, Figure 9 shows what happens in beamforming. This is Opn compared to manufacturer C, which has an automatic beamforming concept. Notice that when speech is coming from in front, they both clean up the signal-to-noise ratio to a certain degree. However, when speech is coming from the side, the preservation of the signal-to-noise ratio is better with Opn than with a beamforming product. That demonstrates the difference between what we are trying to accomplish with Opn versus beamforming. Beamforming is doing exactly what you would expect beamforming to do, which is to preserve a good signal-to-noise ratio for speech coming from in front and suppress anything else coming from another direction. Where we differ is that we don't believe in suppressing sounds coming from the side when there are clearly defined speech signals. That's why we tend to preserve them better with Opn and OpenSound Navigator. That's the design of OpenSound Navigator at work.
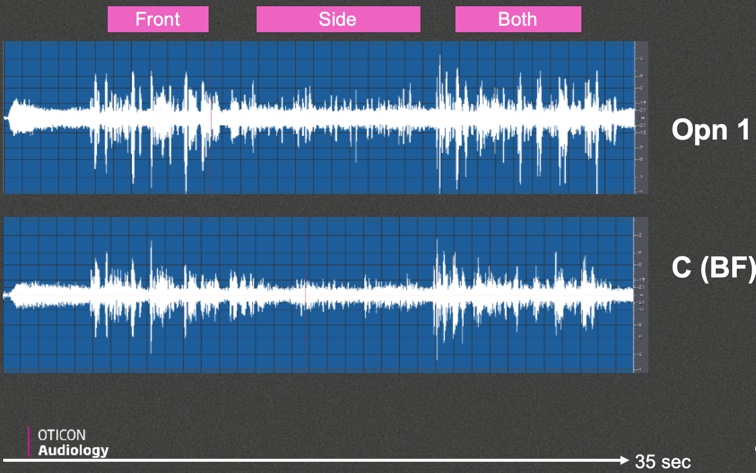
Figure 9. Condition 2 output analysis, Opn 1 vs. beamforming.
Condition 3: Speech from the Front and SSN from Behind
In this next condition, we have speech coming from in front and speech-shaped noise coming from both back angles behind KEMAR. This is a pretty standard situation in which any high-end product should be able to clean up the signal-to-noise ratio. Anything with any directional component plus any noise reduction component should do a reasonably good job of improving the signal-to-noise ratio with speech from in front and noise coming from behind.
Figure 10 shows the output with the unaided signal (top panel) and the output with Opn 1 (bottom panel). You will notice that OpenSound Navigator quickly locks on to the noise signal and then keeps that noise signal at a nice, steady output throughout the 35 seconds of recording and then improves the signal-to-noise ratio by about +5 dB. That's what we expect to happen.
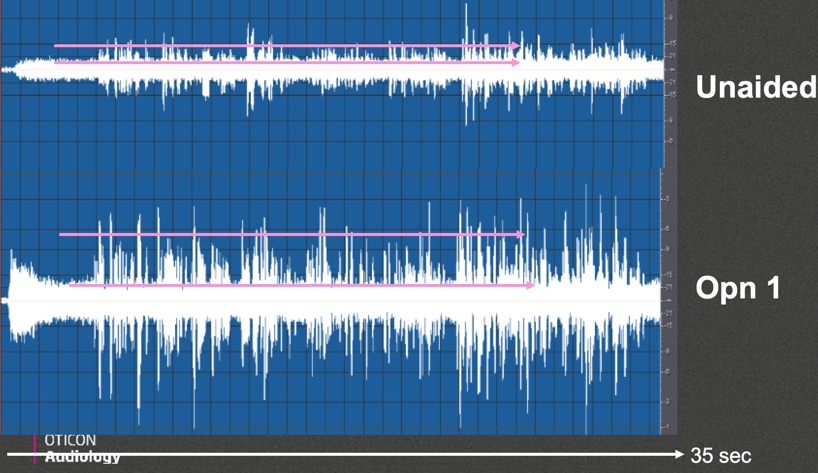
Figure 10. Condition 3 output analysis, unaided vs. Opn 1.
Next, let's compare Opn 1 to products A and B (Figure 11). Product A and B are working in their normal operating mode as being automatic directionality and automatic noise reduction but using more traditional signal processing components; you start to see some difference in the timing of the response to the background of the noise. Let's take a look at where you start to see evidence that the background noise is being reduced compared to the speech. With Opn, that occurs quickly within the first few seconds. In contrast, throughout the first 20 seconds or so of the recording, Product A doesn't quite figure out what it wants to do with the background noise until later in the recording, and then it starts to reduce the background noise significantly. However, that was a long period of time for the patient to have to try to listen to speech in that background of noise. This is a good example demonstrating the quick update speed of OpenSound Navigator as compared to traditional systems.
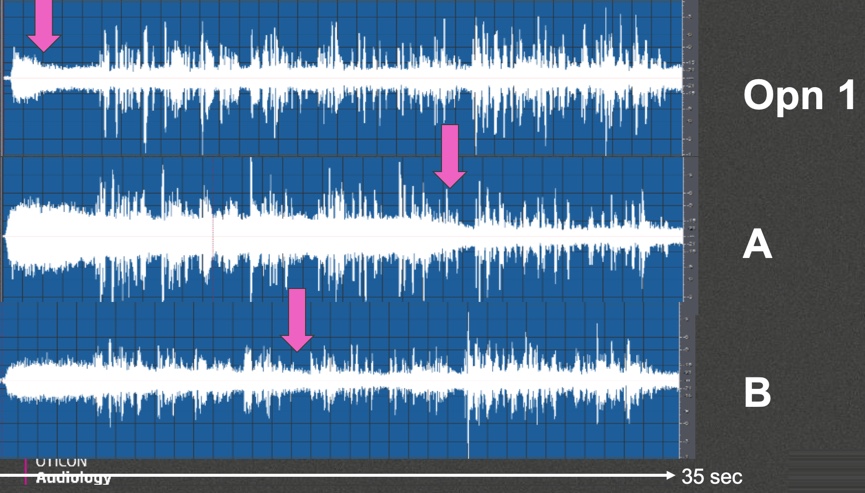
Figure 11. Condition 3 output analysis, Opn 1 compared to products A and B.
Looking at Competitor B on the bottom panel of Figure 11, this is a product that is in automatic mode with a more traditional noise reduction and directionality approach. It has beamforming capability but as a separate program. Under this condition, you also see some delay before it finally settles into its fully noise reduction mode in terms of what it's going to do with that background of noise.
We believe this is a good example of the design difference of OpenSound Navigator versus other products. We disagree with the notion that a lot of hearing care professionals believe that all high-end products work pretty much the same way. We've been able to show that both the design and the function of OpenSound Navigator are more effective than other products in the marketplace.
Condition 4: Speech and SSN from the Front
In this next recording condition, we wanted to challenge the noise reduction effect of the hearing aid. We not only had speech coming from in front but also speech-shaped noise coming from in front. Another factor about this recording condition is that the noise stops halfway through. After the noise has been on for about 10 or 15 seconds, then we stop it. The intent of stopping the noise was to show how quickly the system would recover once the noise came back on. In this scenario, there's no possibility for directionality to do anything to help the signal. It's all up to the noise reduction system to try to do something with that listening situation.
In Figure 12, the top panel shows the unaided condition, and the bottom panel shows the output of Opn. When you look at the performance of Opn, you can see that it latches on to no noise pretty quickly, although, without any directionality, it has to work a little bit harder. Also, notice that the signal-to-noise ratio cleanup isn't quite as effective as when you add the directional component, but remember that this is a very challenging listening environment. This has speech and noise coming from directly from in front. Once the noise stops, you see a stop, and when it starts again, you can see that it takes a second or so before it starts to clamp down again. Again, although this is a challenging environment because there's no directional information to use, you still see the system being able to recognize it as noise and pull the noise out to a certain degree to improve the signal-to-noise ratio.
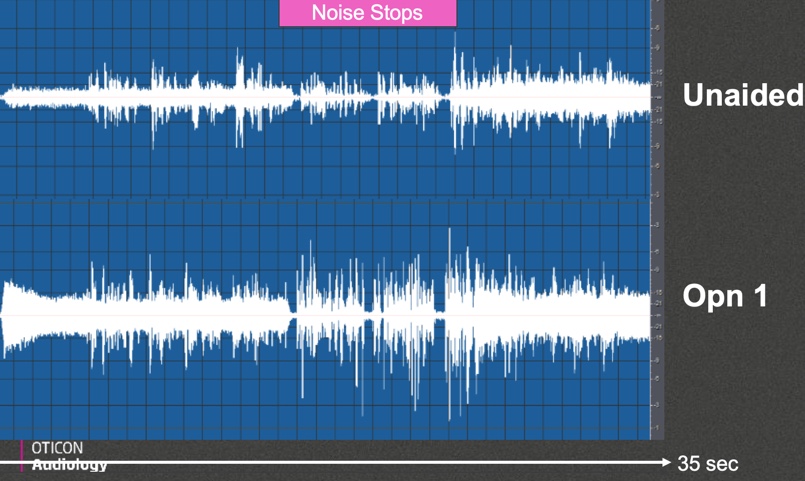
Figure 12. Condition 4 output analysis, unaided vs. Opn 1.
If we compare Opn to product competitor B (Figure 13), you can start to see some of the timing differences. With Opn, you see relatively quick response to noise. With manufacturer B, it takes longer for it to figure out what it wants to do with background noise, both at the beginning of the noise signal and after the noise stops and starts again. The pink arrows are the indication of where it looks like Product B is able to settle down and determine what it wants to do with that noise.
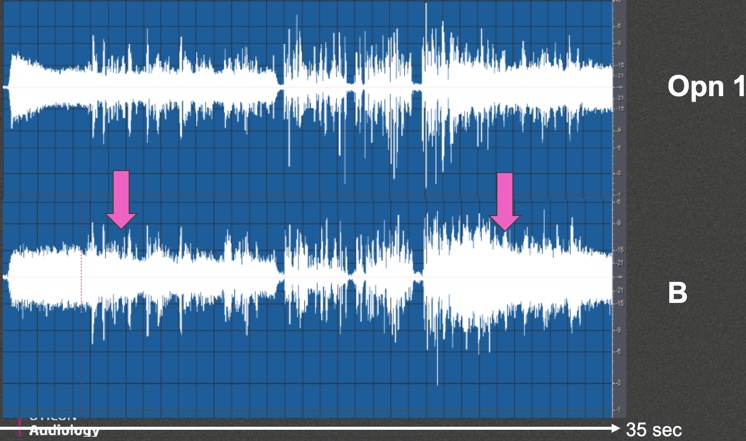
Figure 13. Condition 4 output analysis, Opn 1 vs. Product B.
Condition 5: Speech from the Front and SSN from Front and Behind
In this condition, we had both speech and noise coming from in front like we did in condition 4, but also some speech coming from behind. In this scenario, there is going to be some advantage because you do have the directionality that can help solve the problem to a certain degree.
Figure 14 shows the unaided signal and the response of Opn. Compared to the last recording condition, you'll notice a little bit better improvement in the signal-to-noise ratio. It's not as good as when noise was only coming from behind, but when there was no directional information, the system was more challenged by that situation, although it was able to offer some noise reduction effect. Here, once you add in some directionality, you see some improvement in the noise reduction, which is what you would expect.
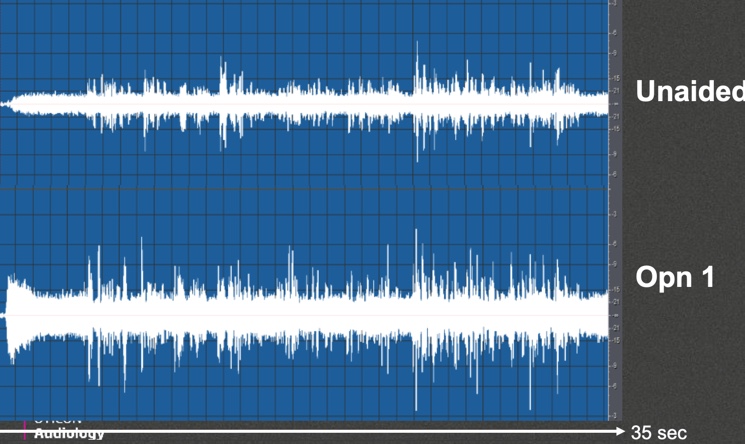
Figure 14. Condition 5 output analysis, unaided vs. Opn 1.
Figure 15 shows all of the products side by side: Opn 1, competitor A, competitor B in automatic mode (B Auto), and competitor B in beamforming mode (B BF). In the beamforming mode, you can see a little bit more suppression of the noise reduction. Notice that in general, the signal-to-noise ratio improvement across the board - especially when you have two talkers - seems to be slightly better preserved in Opn compared to some of the competitors because the products are working in a highly complex listening situation. When you have both noise coming from in front and coming from behind, for example, beamforming can't completely solve that problem because it also must deal with the noise from behind. Product A seems to take longer to identify the noise before it knows what to do with it.
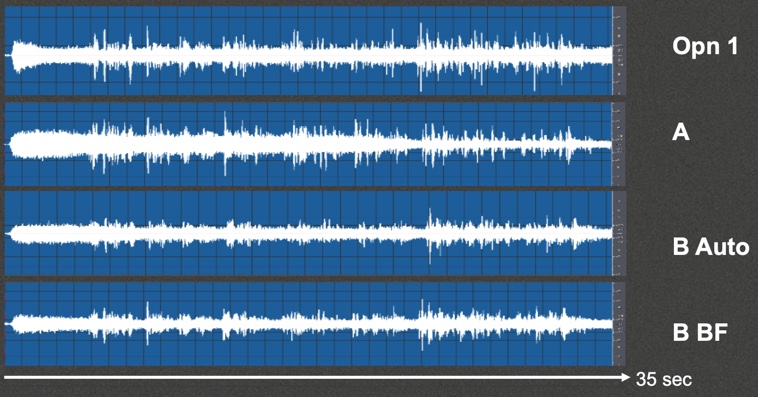
Figure 15. Condition 5 output analysis, all products.
Product B appears to suppress a lot of different things that are occurring, probably driven by the fact that there's also noise coming from in front. When dealing with a broadband noise like speech-shaped noise, traditional noise reduction is not going to effectively remove that from the signal because it is more of a broad-based noise reduction approach as opposed to the noise removal system in Opn. Opn is much faster and much more targeted about the way it can go after noise, even in a broadband noise situation like that. In analyzing all of these different conditions, it is clear that there are some distinct differences between these products and how they handle complex listening environments. This is important to keep in mind when we consider the notion that all products work the same way.
Study: Multiple Talkers in Noise
A few years back when we compared the way these systems work in terms of patient performance, we specifically wanted to see whether or not patients perform differently in different environments when wearing beamforming and traditional noise reduction and directionality. We contracted University of Oldenberg in Germany to conduct testing with speech coming from directly in front of a listener versus speech coming from plus or minus 45 degrees. Again, we were trying to create a comparison between what beamforming, traditional directionality, and OpenSound Navigator would do in an environment like this.
Figure 16 shows that when the speech was only coming directly from in front, OpenSound Navigator was able to effectively outperform traditional directionality in noise reduction. There were no significant differences between beamforming and OpenSound Navigator in this condition (speech from front, noise all around). OpenSound Navigator can match the performance of beamforming in the situation that's specifically designed to highlight the benefits of beamforming.
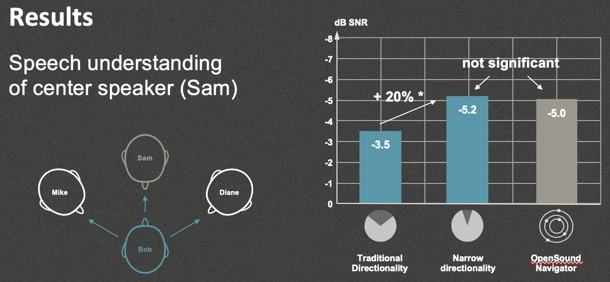
Figure 16. Speech understanding of center speaker.
The next condition involved speech coming from plus or minus 45 degrees, or coming from in front. These were random presentations. In other words, speech could come from any of the three talkers at any point in time. In Figure 17, notice that the performance of OpenSound Navigator was significantly better than traditional directionality in noise reduction, as well as better than beamforming in this condition. The point is that although we can match beamforming when speech is only coming from in front when you consider other people in the talker environment in the front half of the listening field, OpenSound Navigator can outperform the effectiveness of beamforming.
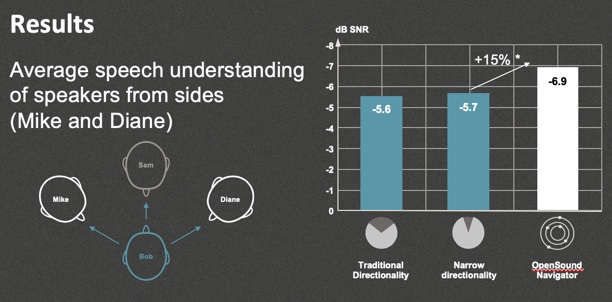
Figure 17. Average speech understanding of speakers from sides.
When you take a look at the technical and the performance data, you can see that OpenSound Navigator definitely is not outperformed, under any condition, by beamforming. In those more naturalistic listening environment conditions, we can preserve clearly defined speech signals better than beamforming, as long as a signal is not coming from directly in the front. With OpenSound Navigator, we have achieved our design purpose of improving patient performance in complex listening environments without having to put unnatural restrictions on our patients.
Opn S vs. Opn
As we begin to wrap up the presentation, I want to talk about what we've done with the release of Opn S. As I said, OpenSound Navigator and Opn S work fundamentally the same way as they have in the last three years, although with Opn S, we did improve feedback cancellation. OpenSound Optimizer is our new system for handling feedback. It was based on the fact that there are two phases to feedback cancellation: a fast phase and a long-term phase. With OpenSound Optimizer, we're able to make significant improvements in the fast-term phase. In traditional feedback systems, feedback typically will become audible before the long-term phase can decide what to do with it. With OpenSound Optimizer, we found a way to stop feedback before it typically becomes an audible issue for the patient and keep feedback at bay until a new long-term solution can be calculated by the system. We did that by improving the speed and resolution of signal processing dedicated to our feedback system. In addition, we have a unique cancellation technique which uses breaker signals in the response of the hearing aid in order to stop feedback before it becomes an audible issue for the patient.
I want to discuss some recordings we did with OpenSound Optimizer, once again using KEMAR. The test conditions involved speech coming from in front and two back speakers with speech-shaped noise at plus and minus 135 degrees. Both speech and noise were at 70 dB. In this case, we used a high-frequency hearing loss, and open domes, because we wanted to challenge the system in terms of feedback to see how different products responded to feedback.
This is the audiogram we'll use with an open dome (Figure 18). As you know, that would be sort of coupling that most audiologists would like to use with the patient, but might not be able to achieve because of the risk of feedback. We decided to push it to this point because we wanted to see how different systems respond. I'm not going to show you all the responses of all the different products, as that analysis isn't complete yet. We'll show you that at a later date. I just want to show some of the preliminary data to highlight how different products will respond in a different way to this challenge.
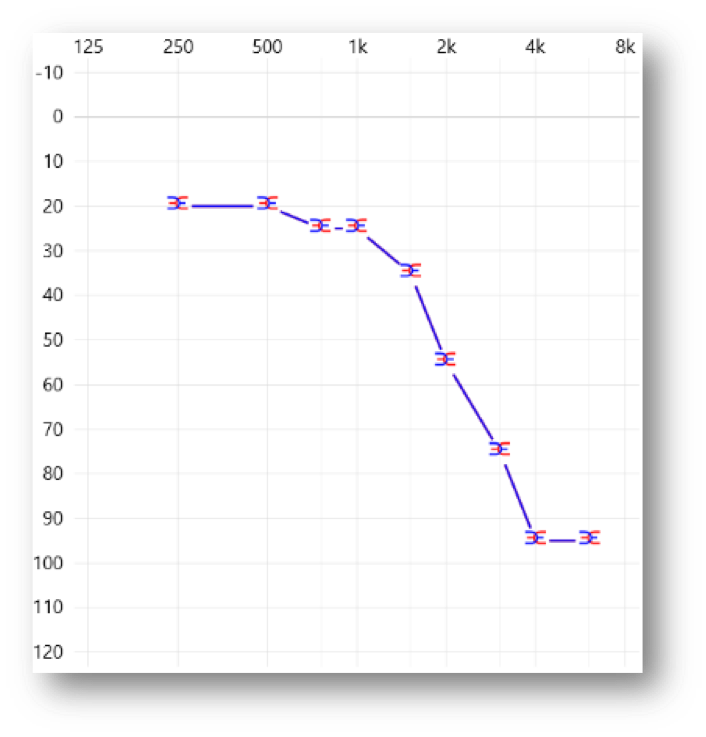
Figure 18. Audiogram of high-frequency hearing loss.
In Figure 19, we're comparing Opn S to competitor A. Competitor A is the same product from the previous test conditions. Notice that in a static situation where there is no feedback present, you can see Opn handling the background noise more effectively and creating a more positive signal-to-noise ratio. In a dynamic situation where we hold a phone up to the ear, we challenge the system via feedback. Once we do that with Opn S and the new feedback system, OpenSound Optimizer, you don't see a feedback signal being created. You only see a maintaining of the good signal-to-noise ratio for the speech signal. With competitor A, you'll notice that you don't see a feedback signal either. If there was a feedback signal, the amplitude would be much greater, and you would see that in the output waveform. What you do notice is that although you don't get feedback out of that system, the overall output of the hearing aid has dropped dramatically. This is an indication of the way this system is going to handle a feedback challenge: by cutting gain significantly.
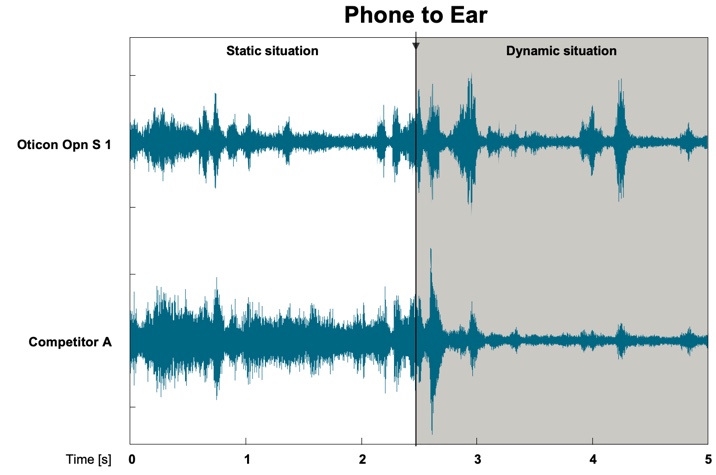
Figure 19. Opn S 1 vs. Competitor A: feedback comparison.
As we revisit this issue that all products work the same way, we can see that is not the case. With regard to feedback, there are systems that you might think are good in terms of handling feedback because you never hear feedback out of them. However, in dynamic situations, they may be applying some dynamic gain reductions to decrease the output of the hearing aid. If the patient runs into a lot of feedback challenges during the course of their day, they might be losing a lot of gain on an ongoing basis. Again, for the purposes of this presentation, we won't do a complete review of the way our system works compared to other systems, as our analysis is ongoing, although we are confident in our preliminary estimates.
Summary and Conclusion
In summary, I believe that these technical analyses combined with the performance data that we've shown have demonstrated that we were able to accomplish our design purpose with OpenSound Navigator: to improve speech understanding in complex environments without unduly sacrificing a natural listening experience. The effectiveness of the directional components and the noise removal components of OpenSound Navigator were clear in those waveforms. The patient performance data is clear. We take a lot of pride in what we were able to accomplish with OpenSound Navigator in an effort to get our hearing impaired patients on par with normal hearing individuals.
References
Axelsson, Ö., Nilsson, M. E., & Berglund, B. (2010). A principal components model of soundscape perception. The Journal of the Acoustical Society of America, 128(5), 2836-2846.
Skagerstrand, Å., Stenfelt, S., Arlinger, S., & Wikström, J. (2014). Sounds perceived as annoying by hearing-aid users in their daily soundscape. International journal of audiology, 53(4), 259-269.
Ohlenforst, B., Zekveld, A. A., Lunner, T., Wendt, D., Naylor, G., Wang, Y., ... & Kramer, S. E. (2017). Impact of stimulus-related factors and hearing impairment on listening effort as indicated by pupil dilation. Hearing Research, 351, 68-79.
Citation
Schum, D. (2019). The Behavior of OpenSound Navigator in Complex Environments. AudiologyOnline, Article 25334. Retrieved from https://www.audiologyonline.com

