
Learning Objectives
As a result of this Continuing Education Activity, participants will be able to:
- The participant will be able to describe how the Adaptive Streaming Volume feature is realized.
- The participant will be able to described the benefit offered by Adaptive Streaming Volume.
- The participant will be able to describe the results of a clinical study which evaluates Adaptive Streaming Volume.
Introduction and Background
In many countries today, over 90% of the adult population owns a mobile phone, and the majority of these are smart phones. Mobile phone use is not just for younger individuals — at least 75 percent of seniors own cell phones, and smartphone ownership is over 50% for the 55+ age group. A couple decades ago, because of cost and inconvenience, calls back home to mom might be reserved for Sunday evening or special occasions. Today, due to the ease of technology, mom may be talking to children and grandchildren several times a day. Importantly, many of these individuals who are now involved in considerably more telephone communication than in years past are also hearing aid users. And even if they are not using their phones for prolonged conversations, they are using their phones more and more to receive and relay important messages. Historically, however, hearing aids and telephones have not been very good companions.
There are several reasons why understanding speech from the telephone using hearing aids can be difficult: there are no visual cues, the bandwidth of the signal may be limited, the coupling of the devices may be difficult or cumbersome, acoustic feedback issues may be present, and interfering background noise often is present. The latter is even more a factor in recent years, as due to the mobile nature of the devices, phone conversations now often occur in much noisier environments than a quiet kitchen or living room.
Traditionally, there have been two common solutions for talking on the telephone while wearing hearing aids. The first, is to use the hearing aid’s telecoil. This requires compatibility, correct positioning, and a hearing aid large enough to house an effective coil. The advantage of this system is that the microphone of the hearing aid is not always active, which leads to an improved signal-to-noise ratio (SNR). An alternative approach has been to simply use an acoustic pathway—that is, channel the output of the telephone acoustically to the microphone inlet of the hearing aid. This especially was a common approach when completely-in-canal (CIC) hearing aids had a large market share in the 1990s. Even with today’s feedback reduction systems, this approach can lead to acoustic feedback issues. The SNR also can be poor, and gain sometimes is not sufficient.
In recent years, hearing aid manufacturers have introduced wireless signal routing for telephone use. These systems may use intermediary transmitters that accept signals from cell phones, and then transmit these signals to the patient’s hearing aid using wireless technology such as Bluetooth. One advantage that this technology offers is that the telephone signal can be streamed to both hearing aids simultaneously, which at least in theory, will assist in speech understanding.
There is limited independent research comparing the different modes of telephone use with hearing aids that are available today. One article, however, which stands out is the recent work of Picou and Ricketts (2011).These authors conducted comparisons of several different telephone solutions, and included many factors which could impact speech understanding. They examined features and variables including: unilateral and bilateral wireless transmission, acoustic telephone coupling, open and closed fitting arrangements, external microphone activation, and background noise level.
One of their findings was that wireless signal streaming was shown to be beneficial compared with acoustic telephone listening. However, this advantage was only evident when the signal was routed to both ears and when hearing aid wearers were fitted with occluding domes — predictably, the open domes allowed for external noise to enter the ear canal, reducing the SNR. Interestingly, for open fittings, when the background noise was 65 dB SPL, the acoustic solution (simply holding the cell phone to the ear) was superior to even the bilateral streaming condition. Given the large percentage of open fittings, there clearly is a need for a method to improve the SNR for telephone listening for these hearing aid users.
The Development of Adaptive Streaming Volume
In this paper, we report on a new algorithm which integrates with our wireless streaming. It serves to overcome the common masking effect of ambient noise leaking into the ear canal, where it may partially or completely mask a desired streaming signal. To this point, we’ve been discussing target streaming signals that are the voice of a far-end speaker in cell phone communication, however, the masking effect also applies to other streamed signals, such as music played back via an external player. Leakage primarily is due to vents in open fittings, but can also be observed to a lesser extent for closed fittings.
To overcome the masking effect of ambient noise, Adaptive Streaming Volume employs a time- and frequency-dependent amplification of the streaming input signal. This extra gain helps in raising the playback level of the streaming signal over the masking threshold of the ambient noise and hence restores audibility of the desired signal. The realization of this application is driven by the observation of the unaided (i.e. without Adaptive Streaming Volume) signal-to-noise ratio (SNR) vs. a desired target SNR (Sauer & Vary, 2006). This concept is illustrated in Figure 1. In each time instant, the algorithm estimates the expected unaided SNR and computes the frequency-dependent gains that are required to realize a predefined target SNR. The definition of the target SNR is frequency dependent. Therefore, special emphasis may be given to mid and high frequency bands as audibility in this frequency region is known to be important for the intelligibility of fricatives and stops.
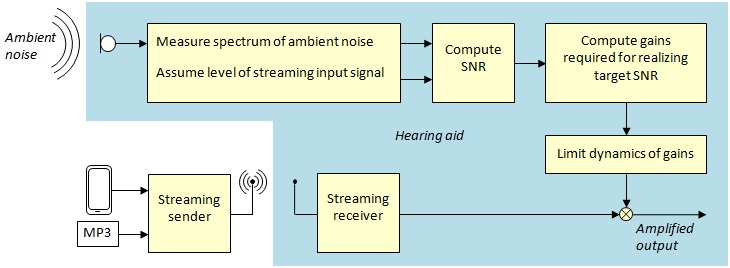
Figure 1. Block diagram of the concept of Adaptive Streaming Volume.
To estimate the unaided SNR, the knowledge of the current noise level is crucial. Therefore, the noise level is continuously measured in different frequency bands using the hearing aid microphone. For the computation of the unaided SNR, we additionally need to know the target signal level. However, by definition, the adaptive algorithm should not counteract any volume changes effected by the user (via volume control of the external audio source); the target signal level is assumed constant.
The development of the algorithm control followed the following premise: “Make the algorithm effective, but in a way that its intervention is not perceived by the user.” This assumption results in a number of measures that follow the gain computation, and that target the optimization of the temporal and spectral dynamics of the adaptive gain.
The temporal dynamics of the Adaptive Streaming Volume is crucial for attaining a high user acceptance. For this reason, it has to satisfy conflicting requirements. On one hand, the algorithm should react timely to any change in noise level; a gain that reacts slowly would fail in restoring full audibility in case of quick noise level jumps, and it would produce unwanted smearing of the gain in case of noise level dips. On the other hand, it must not react too quickly, as in this case the control would become noticeable by the user, which would reduce user acceptance.
Besides the temporal dynamics, spectral dynamics need to be controlled by the algorithm (e.g. by limiters), as excessive spectral fluctuations of the Adaptive Streaming Volume would result in colorations of the target signal, which again would lead to a low user acceptance.
Finally, the overall output level needs to be controlled to avoid levels that exceed the individual loudness discomfort level. In hearing aids, this function is realized by dynamic compression. An electroacoustic example of the Adaptive Streaming Volume processing is shown in Figure 2. In this example, we measured the mean spectra with the hearing aid fitted to the KEMAR, using an open-dome Siemens binax RIC product. The streaming was a stationary speech-shaped noise delivered via the Siemens remote (i.e., easyTek). The ambient noise was pink noise at 72.5 dB SPL (A).
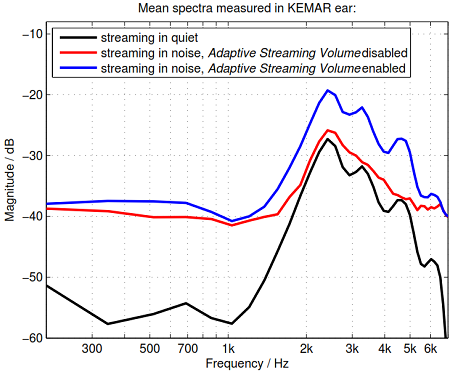
Figure 2. Mean spectra of a streaming signal measured via KEMAR ear, using an open dome Siemens binax RIC product. The curves show the mean spectra for a streaming in quiet (black), for streaming in pink noise while Adaptive Streaming Volume was disabled (red), and the mean spectrum for streaming in pink noise while Adaptive Streaming Volume was enabled. The gain applied by Adaptive Streaming Volume raises the SNR and effectively restores high frequency details that were drowned in noise before.
As shown in Figure 2, the original streaming signal in quiet (black curve) becomes masked when ambient noise is present and Adaptive Streaming Volume is disabled (red curve). In particular, the high-frequency details, present in the original signal (black), are drowned in the presence of the ambient noise (red). Observe, however, that the relationship changes, when the Adaptive Streaming Volume is enabled: the application of the adaptive gain raises the SNR and successfully restores the original high-frequency details. In the following section we will see that in real life, with non-stationary speech signals as opposed to the stationary speech-shaped noise used here, the benefit is even greater.
Clinical Study of the Adaptive Streaming Volume Algorithm
Given all the important considerations reviewed in the previous section, it clearly was important to conduct clinical efficacy studies of this new algorithm. In particular, we were interested in examining the impact that noise-dependent streaming technology in hearing aids would have on speech intelligibility and the perceived listening comfort for the hearing aid user.
Participants and Hearing Aids
Sixteen individuals participated in this study, 4 females and 12 males. The participants were all experienced users of hearing aids with an average age of 68 (std. 8.8) years. The participants were selected to meet the criteria of a bilateral mild to moderately-severe, sensorineural hearing loss. They were matched to two different groups: Group 1 (n=8): the subjects with milder hearing loss were fit bilaterally with mini-BTE
Siemens Pure receiver-in-the-canal style devices and open domes. Group 2 (n=8): these subjects, with more severe hearing loss were fit bilaterally with closed ear molds, with appropriate venting (no larger than 2mm). Mean audiograms averaged across the right and left ears separated for both groups are shown in Figure 3. The participants were paid on an hourly basis for their participation.
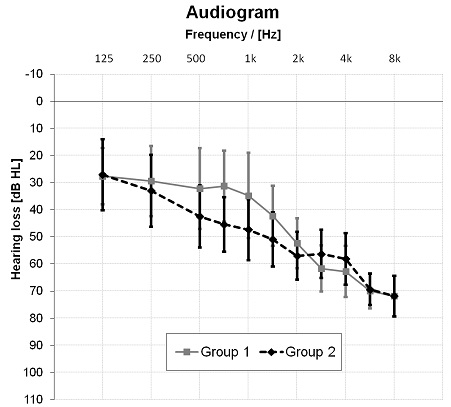
Figure 3. Mean hearing loss with standard deviation averaged across both ears for open dome group (Group 1) and closed mold group (Group 2).
Questionnaire
The self-assessment questionnaire used in this study comprised of questions on the perceived speech intelligibility, listening effort and sound quality of Adaptive Streaming Volume. Each item is answered using a 5-point scale, where #1 would indicate a very bad assessment and #5 a very good assessment. In addition, the participants had to rate the perceived loudness of the streaming signal while Adaptive Streaming Volume was enabled. For these items on the 5-point scale, #1 would indicate “much too soft,” #3 “right loudness,” and #5 “much too loud.” The questionnaire was administered by pencil and paper.
Procedures
The Siemens hearing aids were fit bilaterally using Connexx 7 software to the Siemens proprietary prescriptive method for experienced users. There was no fine tuning conducted. Two different programs were prepared in the hearing aids, where one provided the commonly used application, and another the Adaptive Streaming Volume described earlier.
Following the fitting of the hearing aids, they were connected via Bluetooth to a Siemens remote control that transmitted the sound samples for the evaluation of the streaming performance. For the laboratory measurements, the input was delivered via auxiliary cable. For the simulation of a phone call, the Siemens remote was connected via Bluetooth to a commercial mobile phone. The laboratory test condition was an eight-speaker-circle surrounding the participant, providing a fluctuating traffic scenario (68.5 dB) and a steady pink noise (72.5 dB).
First, an adaptive speech reception threshold (SRT) measurement was conducted using the 20 sentences procedure of the German Oldenburg Sentence Test (OLSA; Wagener, Brand, & Kollmeier, 1999) in the above described noise scenarios. The sentences were transmitted via the auxiliary path to the hearing aids. Their level was adapted in consequence of the achieved speech intelligibility to estimate the 50% SRT. After two training trials, individual SRTs were collected for the streaming program, with and without the Adaptive Streaming Volume.
In the second part of the experiment, the subjective speech intelligibility and listening effort was collected while the participants listened to an audio book read by a female. In addition to these measures, the subjects also rated the sound quality of the transmission of the audio book and a popular music piece. For this testing, the auxiliary and Bluetooth input were set to a level of 60dB (SPL) that was a comfortable perceptible transmission level within the hearing aids for all subjects in quiet.
A final portion of the research protocol was to evaluate the same attributes as before for an actual phone call. For this evaluation, the speech signal was a German triplet digit test (Wagener, Eeenboom, Brand, & Kollmeier, 2005; Wagener, Bracker, Brand, & Kollmeier, 2006). This was presented via a Bluetooth connected mobile phone to a landline telephone number, where the test was provided.
This test was originally developed for hearing impaired screening. It comprises of digits from 0 to 9 (7 is left out because of its two syllables) that are clustered in triplets, that are usually embedded in background noise. For our purpose only the digit triplets in quiet were presented; the background noise was delivered in the laboratory. The participant’s response is given via the telephone keypad. Similar to other adaptive speech testing, in dependence of the error rate of a given participant, the intensity level of the triplets is adapted to estimate the 50% SRT. In order to evaluate the real-world advantage of the Adaptive Streaming Volume, this same digit test was repeated on a busy city street.
Results and Discussion
The purpose of this investigation was to determine the impact that the Adaptive Streaming Volume had on the speech intelligibility and sound quality perception of streamed speech and music. The average SRT measurements with standard errors for the OLSA test are shown in Figure 4. Note that for the fittings with open domes, the SRT was -3.9 dB in the traffic noise and -2.1 dB in the pink noise scenario, when streaming without Adaptive Streaming Volume. This means that the comfortable streaming level in quiet is already too soft to reach 50% speech intelligibility. This also holds true for the group with more severe hearing losses, using mostly closed ear molds. Their SRTs were -6.6 dB and -3.2 dB for the two different scenarios without Adaptive Streaming Volume.
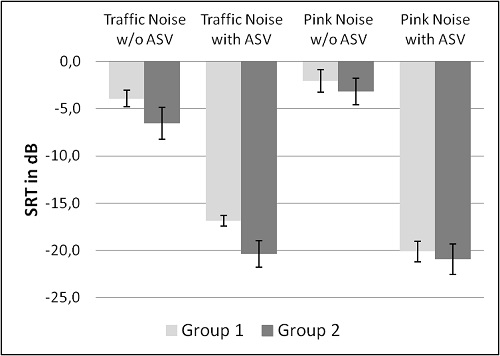
Figure 4. SRTs for Oldenburg sentence test with standard error averaged across subjects fit with open domes (Group 1) and ear molds with up to 2mm venting (Group 2) with and without Adaptive Streaming Volume.
Observe that when Adaptive Streaming Volume was provided, a large SNR improvement was present. In traffic noise, the SRTs improved by about 13 dB for open fittings, and 14 dB for closed. An even greater improvement was observed for listening in pink noise (~18 dB for both groups).
It is also important to examine how the loudness and sound quality was perceived when the Adaptive Streaming Volume was activated. Figure 5 shows the results averaged across both groups of participants.
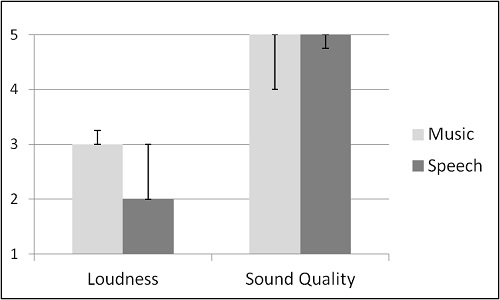
Figure 5. Median of loudness and sound quality perception of Music (black bars) and Speech (dark grey bars) in traffic noise averaged across all subjects. Error bars indicating the 1. and 3. Quartile variation of values. For loudness a value of 1 indicates “much too soft”, 3 “right” and 5 “much too loud.” Sound quality 1 indicates “very much artifact,” and 5 “no artifact at all.”
As shown in Figure 5, for speech content, the loudness of the automatic adapted streaming was perceived as just right, while music was perceived as just slightly too soft. On average, Adaptive Streaming Volume did not produce any annoying artifacts, such as unbalanced sound or steering artifacts.
Recall that another component of this clinical study was to examine speech understanding on the telephone using a unique adaptive digit test as the speech signal. This testing was conducted in the same laboratory setup as the SRT measurements mentioned above. The same testing also was conducted on a busy city street, with naturally occurring traffic noise as the competing stimulus. The results of this testing are shown in Figure 6. Similar to the previous testing, the Adaptive Streaming Volume algorithm resulted in an improved SRT-50 for both groups for both listening conditions. Averaged improvement in SRT was 11-12 dB for the laboratory listening situation, and 10 dB for the real-world traffic scenario. The improvement was very similar for both groups (see Figure 6). For both listening situations, the perceived listening effort also significantly decreased (using a 5 point rating scale). Without Adaptive Streaming Volume, listening effort was rated from #3 to #4, which was “moderate to considered effort required.” With Adaptive Streaming Volume activated, listening effort was rated #1 for all participants, which was designated as “no effort required”.
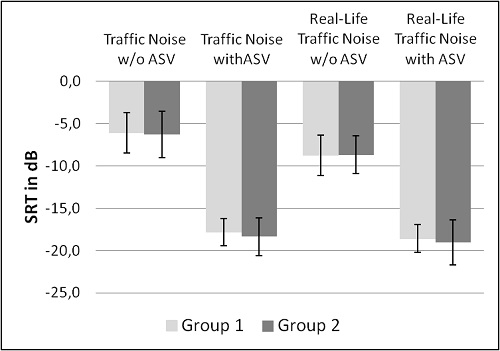
Figure 6. SRTs for German triplet digit test with standard error averaged across subjects fit with open domes (Group 1) and ear molds with up to 2mm venting (Group 2) with and without Adaptive Streaming Volume.
Summary
Understanding speech on the telephone has long been a problem for hearing aid users. Despite new wireless streaming applications, when background noise is present, and especially when an open fitting is applied, modern technology often is little better than using an acoustic telephone.
In this paper, we describe a solution which can significantly improve speech recognition for these difficult listening situations. The new Adaptive Streaming Volume algorithm keeps the possibility to adapt the general streaming volume to individual loudness preferences by changing general loudness of the source by the hearing impaired himself or of the basic level within the software by the hearing care professional. In addition, it provides time and frequency dependent amplification of the streaming input signal, providing a boost in gain when necessary to place the streamed signal over the masking threshold of the ambient noise, improving the SNR, and restoring audibility of the desired signal.
Clinical research with this new algorithm has shown substantial SNR improvement when this algorithm is activated. In adaptive speech tests, the SRT-50 in background noise was improved as much as 18 dB in laboratory conditions, and by 10 dB in real-world telephone listening. Moreover, the improvement was present for an open fitting, as well as closed ear canal conditions. All subjective reports were also highly positive, making this a viable feature for all hearing aid users using streaming of any type.
References
Picou, E. M., & Ricketts, T. A. (2011). Comparison of wireless and acoustic hearing aid-based telephone listening strategies. Ear and Hearing, 32(2), 209–220. doi: 10.1097/AUD.0b013e3181f53737
Sauert, B. & Vary, P. (2006, May). Near end listening enhancement: Speech intelligibility improvement in noisy environments. Proceedings of Independent Component Analysis and Signal Separation (ICASSP), 493–496.
Wagener, K., Brand, T. & Kollmeier, B. (1999). Entwicklung und evaluation eines satztests für die deutsche sprache. Zeitschrift für Audiologie, 38, 4-15.
Wagener, K., Eeenboom, F., Brand, T. & Kollmeier, B. (2005, February). Ziffern- Tripel-Test: Sprachverständlichkeitstest über das telefon. Paper presented at the 9th Annual German Society of Audiology (DGA) meeting, Göttingen, Germany.
Wagener, K., Bräcker, T., Brand, T. & Kollmeier, B. (2006, March). Evaluation des Ziffern-Tripel-Test über kopfhörer und telefon. Paper presented at the 9th Annual German Society of Audiology (DGA) meeting, Cologne, Germany.
Cite this Content as:
Fischer, R., Mauler, D., & Klop, L. (2015, June). Improving cell phone listening with hearing aids: a new adaptive streaming volume algorithm. AudiologyOnline, Article 14343. Retrieved from https://www.audiologyonline.com.



