
 From the Desk of Gus Mueller
From the Desk of Gus Mueller

Let’s talk programming hearing aids. To take us to a reasonable starting point, we have two well-researched prescriptive fitting approaches, the NAL-NL2 and DSLv5.0. Our patients have diverse listening needs for a variety of inputs, and in general these algorithms are a compromise of fitting strategies, to provide something that is “pretty good” for all situations.
It was not too many years ago, that we often would then add a second program for a specific listening situation, and change programming accordingly—e.g., less gain in the lows for listening in background noise. Today, much of this is automatic, as we rely heavily on the hearing aid’s classification of the input signal, and the automatic transition to the default signal processing associated with that classification.
Automatic is nice, but does all this really work? One specific situation that is important for many of our patients is listening to music. A recent Audiology Today article that caught my eye, from Emily Sandgren and Josh Alexander of Purdue, compared the ratings of the standard fit-to-target program to the manufacturer’s default music program. These comparisons were made for the premier hearing aids of seven major manufacturers. As you might expect, some products were better than others. But perhaps more importantly, the researchers found that for only three of the products, the music program was rated the best. For two manufacturers, there was no difference, and for two products, the basic fit-to-target program was rated significantly better than the music program for listening to music! This of course simply means that, at least for some products, our patients need us to program the hearing aids correctly for music listening.
So how do we do this? How about we bring in someone who has written a book on this topic. Marshall Chasin, AuD, is Head of Audiology at the Musicians' Clinics of Canada, Adjunct Professor at the University of Toronto and at Western University. His many awards include the 2012 Queen Elizabeth II Silver Jubilee Award, the 2013 Jos Millar Shield award from the British Society of Audiology, and the 2017 Canada 150 Medal.
Dr Chasin has authored several books, including the aforementioned Music and Hearing Aids, published last year by Plural. He writes a monthly column in Hearing Review, is a columnist for Hearing Health and Technology Matters, and is the Editor of the (open-access) journal Canadian Audiologist, where you’ll always find interesting audiologic reading, such as the recent Issue 5 of this year, dedicated to “Audiology Humor (or maybe Humour).”
With all these years of awards and accomplishments that Marshall has under his belt, it’s ironic that what I consider to be his greatest achievement just came to fruition a few weeks ago. He was the acoustic brains behind a metal walkway at the airport in Munich, Germany, that contains different sets of carefully spaced groves in the metal. When people are going down the walkway, pulling their roller-bag wheels across the groves, they hear the melody of the very popular Bavarian drinking song “Ein Prosit der Gemütlichkeit.” Appropriately, the walkway was installed in time for this year’s Octoberfest.
So, here’s what I’m thinking. If this Marshall fellow can figure out how to get a rolling suitcase to play a German drinking song, he probably also can give us some good advice regarding music and hearing aids.
Gus Mueller, PhD
Contributing Editor
Browse the complete collection of 20Q with Gus Mueller CEU articles at www.audiologyonline.com/20Q
20Q: Optimizing Hearing Aid Processing for Listening to Music
Learning Outcomes
After reading this article, professionals will be able to:
- Discuss how to select software programming that is optimized for music.
- Explain the engineering limitations of most modern hearing aids for music.
- Identify some simple clinical strategies to improve a hearing aid for music.

1. This sounds like a great topic, but I'm pretty sure the hearing aids I fit already have a well-researched music program?
Manufacturer-designed programs can be useful in some instances, but there are more differences between manufacturers than similarities, and some programs are not well-thought-out or even based on the available research.
Some manufacturers use a set of electro-acoustic parameters that are more speech-like than music-like, often specifying a more active WDRC series of settings (and compression ratios) than is necessary or even preferable. Mueller and his colleagues (2021) were able to demonstrate when comparing six premier hearing aids from different manufacturers that when the manufacturer’s “preferred fitting” was selected, the actual maximum power outputs varied by up to 30 dB from manufacturer to manufacturer for the same audiogram, so verification and reprogramming is not only important for a speech program but for a music program as well. In other words, if the hearing aids aren’t programmed correctly (fit to a validated target) for speech, they probably won’t be optimal for music either. The following is from Mueller et al. (2021), showing the variation in MPOs from different manufacturers for the same audiogram.
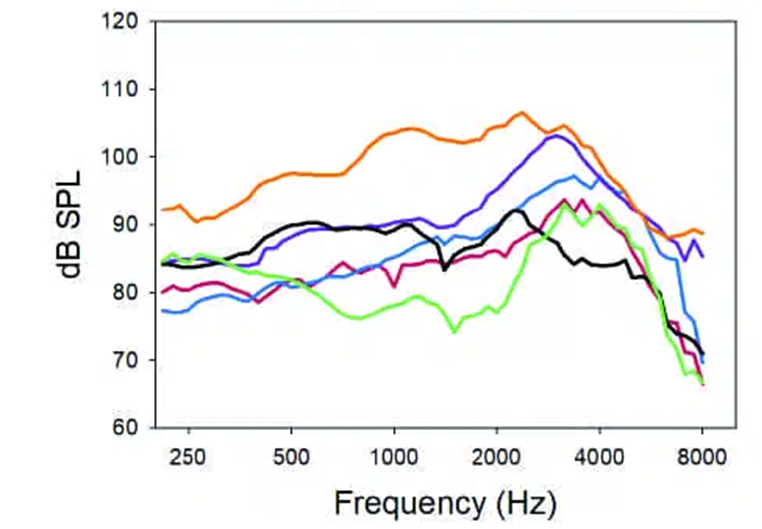
Figure 1. Wide variation in MPOs based on the same audiogram from different manufacturers. From Mueller et al. (2021).
Assumptions are frequently made that “more is better,” and this includes, for example, wider frequency responses for music programs than for speech programs. Although this sounds like a mother-and-apple-pie statement, this is rarely the case when the research is examined- typically, similar frequency responses will be the goal. Even worse are the frequently erroneous assumptions that a “first fit” program is sufficiently close to the target.
2. What about the automatic music classification program? Are there problems with that, too?
Other than differences in electro-acoustic settings and functions within the DSP, there are differences in detectors for the classification and automatic program setting. And, like the specification of certain electro-acoustic parameters, in many cases, the approaches are based more on assumptions than on research and clinical data. Automatic classification, like other DSP parameters, can be highly variable from manufacturer to manufacturer. Clinically, an algorithm, such as automatic classification, that samples the environment and makes changes is not ready for prime time.
Yellamsetty and colleagues (2021) showed that different hearing aid manufacturers used different DSP algorithms in their designs- some used detectors that were based on overall level, and others used algorithms based more on SNR. They were able to show dramatic differences among manufacturers. For example, for music that was 70 dB SPL, a fairly common listening level, two of the five manufacturers only correctly identified it as music ~60% of the time.
Where hearing aid manufacturers are very good at communicating the existence (or not) of an automatic classification function, they do not provide the clinician with information about what’s under the hood- how do these classification systems actually work? This is yet another reason why the audiologist needs to be the one to ensure that the hearing aids are properly programmed for music listening.
3. Okay, you’ve convinced me. I’m ready to learn! Where do we start?
How about how the A, Bb, and C#’s of music are related to the common audiologic test frequencies? Every field of study has their own jargon and terminology, and of course, music is no exception. As you know, audiometrically, we typically test hearing using pure tones ranging from 250 Hz to 8000 Hz. Middle C on the piano – the note that separates the treble clef from the bass clef is close to 250 Hz… actually 262 Hz for those purists out there. And the top note on the piano is close to 4000 Hz. So, we typically test hearing from the middle of the piano keyboard to an octave above the top note of the piano.
And like speech, there is not just energy at only one frequency. A note like middle C not only has energy at 262 Hz, but also integer multiples above that. Many musicians walk around with an A (440 Hz) tuning fork in their pockets, and while that may seem odd (which it is), this represents the sound of the second space on the treble clef, which has its fundamental at 440 Hz with integer multiples of harmonics above that- but musicians just call it A, and Canadian musicians call it “eh.”
4. Why should we care whether a hearing aid is set up for music as opposed to speech?
There are many differences between the acoustics of music and that of speech, but among the differences, the most important is that music is typically louder, even when listened to on the radio or while streaming. Whereas a typical average sound level of speech at about 1 meter is on the order of 65 dB SPL RMS, that of even quiet music can easily be in excess of 80 dB or 90 dB SPL RMS with peaks that are also much higher than speech.
And although we routinely deal with a concept called “crest factor,” we may not explicitly recall that phrase. The crest factor is the difference in decibels between the average or RMS of a signal and its peak. For speech, the crest factor is on the order of 12 dB, but musical instruments have less damping than the human vocal tract, so music typically has crest factors that can be 6-8 dB higher, with peaks sometimes exceeding 20 dB higher than the RMS level. Even quiet music can then have peaks that easily exceed 100 dB SPL or even higher.
Incidentally, we deal with the crest factor clinically when we run a hearing aid in a test box and measure the gain, OSPL90, frequency response, and other parameters. The “reference test gain” is set at 77 dB below the OSPL90. Well, 77 dB is 65 dB + 12 dB. The term “65 dB” represents average speech levels, and the “12 dB” term is the crest factor, suggesting that the peaks for speech are roughly 12 dB higher than the RMS average speaking level.
5. You mentioned the difference between the loudness of music vs. speech. What else?
There are other differences relating to the nature of the harmonic structure of music. Music is only made up of the fundamental and its harmonics (with the exception of percussion, but drummers are weird in any event). In music, if I were to play or listen to the piano playing A at 440 Hz, not only would the piano generate a pure tone at 440 Hz, but also at 2 x 440 Hz or 880 Hz and 3 x 440 Hz or 1320 Hz and so on. It's harmonics all the way up. Speech is made up of lower frequency harmonically rich sounds like vowels, nasals, and the liquids ([l,r]), and these sounds (also known as sonorants) have most of their energy below 2000 Hz, but also higher frequency consonants such as the ‘s’, ‘sh’, and other fricatives and affricates. Unlike the sonorants, these sounds (also known as obstruents) are characterized by broad bands of noise. It really doesn’t matter whether an ‘s’ begins its energy at 4000 Hz and up or 3800 Hz and up- it’s just a broad band of noise without any harmonic content. It’s this high frequency region that differentiates music (high frequency harmonics) from speech (high frequency noise bands). This has implications for frequency lowering algorithms that lower the frequency of certain bands of energy. We can lower a broad band slightly without anyone noticing, but if we were to lower a harmonic (even ½ of one semi-tone) the music would sound dissonant.
Having said this, both music and speech are similar in that, for the most part, their long-term average spectra are similar, having most of their energy in the lower frequency region, and both extend quite a bit over most of the piano keyboard range. Music does have some energy on the left side of the piano keyboard, whereas speech does not, but this turns out not to be a large issue, especially when hearing aid venting and the popular open instant-fit tips will allow a significant amount of very low frequency sound energy to enter the ear canal, bypassing the hearing aids.
6. I have some patients who fondly recall their old analog hearing aids for listening to music. Are there any commercially available analog hearing aids that I can recommend?
This is actually a two-part question- why do they fondly remember analog hearing aids, and was their hearing better 30 years ago when they wore analog hearing aids?
Let’s deal with the first part first…If a hearing aid has been optimized for that patient and verified with real-ear measures, then even an extreme audiophile should not be able to discern a difference between a signal that has been processed with analog technology versus a digital signal processing approach. Having said this, the analog hearing aids of the 1980s used a form of high-level compression- with the modern form of WDRC not becoming widely used until 1988. In most cases, the hearing aids functioned linearly for most of their operating range, and this lesson has not transferred clinically when using digital hearing aids. If compression is required (more of a cochlear issue than a speech vs. music issue), the compression ratio should be very low, perhaps only 1.7:1 at most. In cases where there is significant venting, the hearing aid system will function even more linearly over most of its range since low frequency energy enters through the vent, bypassing the DSP processing. (Kuk and Ludvigsen, 2003).
Also, many of the music media in the 1980s and early 1990s were not as flat as more modern mp3 audio files. Many had inherent resonances (e.g., AGFA 465 tapes), especially in the mid-range around 1500 Hz, which imparted a “warmth” that is not typically found with modern recorded music. Taking all of this together, a more linear WDRC setting (especially for streaming music that has already been compression-limited once already) and perhaps programming 4-5 dB more gain in the 1500 Hz region than the fitting target specifies may bring back the warmth of recorded music from the 1980s.
Counseling may be needed to “remind” the patient that their hearing was probably better 30 years ago, so it’s like comparing apples to pencils- both are tasty but have nothing in common.
7. Is there a drawback of digital hearing aids for music?
When digital hearing aids first became available in the early 1990s, the quality of amplified music took a major step backwards and this is because digital hearing aids require an “analog to digital” (A/D) converter. Because of many issues relating to technology of that era, the maximum sound that could enter a hearing aid and be converted to digits was on the order of 90 dB SPL. This posed no problem for speech- being on the order of 65-70 dB SPL with peaks on the order of 12-15 dB- the maximum levels of speech could successfully be digitized without any concern of overdriving the A/D converter. The same could not, however, be said of even quiet music. Given the listening levels of music, and the associated higher peaks, many of the higher sound level elements of music were clipped at the A/D converter stage resulting in similar acoustic experiences as having a head room output problem where the MPO is set too low.
Regardless of the software DSP and settings, this front-end distortion could not be resolved. Once the amplified music was distorted, no changes performed later in the amplification chain could improve things. The literature has given several phrases for this, such as “peak input limiting level” (Chasin and Russo, 2004), “extended input dynamic range” (Plyer, Easterday, and Behrens, 2019), and “upper input limiting level” (Oeding and Valente, 2015).
A useful metaphor here is trying to enter a room where the top of the door is too low (or perhaps the door height is fine, but the person walking through the door is quite tall). Unless the door height is increased, or the person walking through the door ducks down, there will be an unfortunate outcome.
While many hearing aid manufacturers have addressed this problem, others still have not.
8. How can we do an “end run” around this problem in the clinic? For example, I may have a patient who loves their hearing aids for speech but is less than excited about the quality of the music that they hear.
There are several things that can be done clinically to improve the quality of amplified music. Also, if these techniques do work, they can be used as diagnostic indicators that there is a lower peak input limiting level than what would be necessary for optimal music listening.
The first strategy is to have your patient turn down the volume of the radio or streamed input to their hearing aids, and if necessary, turn up the hearing aid volume (which is later in the hearing aid processing). This is like ducking under a low-hanging doorway or bridge, and then digitally standing up again once through that A/D conversion stage. If this works better than the converse- increasing the volume of the radio or the input streamed music- then this is clear evidence that that particular hearing aid worn by your patient cannot handle the higher levels associated with music without distortion. (Chasin, 2006; Chasin and Russo, 2004)
Another strategy that can be useful is to simply have your patients not wear their hearing aids while listening to, or playing live music. For patients with up to a 60 dB HL hearing loss, all fitting formulae would only specify 1 or 2 dB of gain for higher level inputs such as music (Chasin, 2012).
9. How has the hearing aid industry responded to their hearing aids having a low “peak input limiting level”?
Many, but not all, hearing aid manufacturers have now responded to this technical requirement for having a “front-end” A/D converter that will not distort with the higher sound levels associated with music. Some hearing aid manufacturers may only offer this advanced technology in only their premium hearing aids, so it’s important to talk with your representative.
One approach, which is used by almost all hearing aid manufacturers now is to use an analog compressor that runs off the pre-amp of the hearing aid microphone, prior to the A/D converter. This reduces the input to a level that is within the operating range of the A/D converter. In most implementations, there is a digital expansion which is the mirror image of this analog compression, such that the music is not significantly altered.
Another approach uses a “voltage multiplier,” which can be added in to any circuitry and this allows the highest level that an A/D converter to receive inputs that are up to 6 dB greater without distortion.
And a third approach is to use “post 16 bit” hearing aid architecture where the maximum level that an A/D converter can handle can be substantially higher- up to a 6 dB/bit increase in the input limiting level.
In practice, hearing aids tend to use a combination of some or all of these technical approaches with modern technologies. (Chasin, 2022)
10. Are there any other benefits for optimizing a hearing aid for both speech and music as an input?
Other than music, which tends to be higher level (and with higher level peaks) than speech, there is indeed one other input to a hearing aid that will benefit from optimizing the front-end A/D conversion characteristics of hearing aids- the hard of hearing patient’s own voice. While speech at 1 meter is on the order of 65 dB SPL, a hearing aid user’s own voice can be in excess of 100 dB SPL at the level of their own hearing aids. Specifically, their own voice may have an RMS level on the order of 84-85 dB SPL (Cornelisse, Gagne, and Seewald, 1991), the additional peaks will be in excess of 100 dB SPL. Therefore, resolving this “front-end” A/D conversion problem for music, will also provide patients with a clearer representation of their own voice. This is not something that hearing aids have ever been able to provide in the past.
11. What about differences in frequency response between a speech and a music program?
The specification of frequency response is more of a cochlear issue than being related to the nature of the input stimulus per se. The short answer is that there should not be any significant differences between programmed frequency-specific gain for speech vs. music. If there is programming and technology room than will allow your patient to obtain more high frequency gain for a music program, you should go back and also apply that additional high frequency gain to all of the other speech programs as well. Moore and his colleagues (Moore and Tan, 2003; Moore, Füllgrabe, and Stone, 2011) have published on both the desired low frequency limit as well as the higher frequency limit of hearing aids, and their work is equally applicable to speech and to music. They have found that a lower frequency limit of 55 Hz is desirable. As far as the higher frequency limit, research also from Brian Moore’s laboratory have shown that there are benefits of extending the frequency response to at least 6000 Hz (Moore and Tan, 2003). Not only does this provide the necessary fundamental and harmonic cues for music and provide the hearing aid user with the greatest chance of audibility for the higher frequency speech cues, but provides us with an improved spatial awareness as well as other localization cues (such as vertical localization) that many people with better hearing may experience.
12. 55 Hz? I have never seen anything that low in a spec sheet. Did you just make a mistake?
I have been known to make the occasional mistake, but this isn’t one of them. It is true that the 55 Hz number was a laboratory test condition that indeed may not be available with commercially available hearing aids, but many of our patients are fit with hearing aids that can provide them with significant sound energy down to 55 Hz simply because of hearing aid venting. Unamplified low frequency sound can enter through venting and earmold leakage and thereby provide the listener with, in many cases, sufficient low frequency sound information. Even “closed” instant-fit tips have considerable venting at 250 Hz and below.
While it is true that there is no speech information below one’s fundamental frequency (roughly an octave below middle C and in my case, around 125 Hz), there can be important lower frequency fundamental bass note energy as well as its higher frequency harmonics, that can be heard in this lower frequency range.
And we can’t forget Margo Skinner and Joe Miller’s (Skinner and Miller, 1983) important work from the early-1980s showing that a “balance” between lower frequency energy and higher frequency energy is crucial for optimal intelligibility and naturalness. If indeed, with sufficient venting, an extended low frequency response can be accomplished for music, then this has implications for an extended higher frequency response for that same music program that would not necessarily be the case for a speech program- this is one exception to the rule that the frequency response for both a music program and a speech program, should be the same.
13. Frequency lowering, in all of its various forms, has sometimes been recommended for speech programs. Is this something that might also work for listening to music?
What a good (and important) question. Like the frequency response of a hearing aid, frequency lowering is related due to the limitations of a damaged cochlea. And it is quite true that frequency lowering technology has been successful for some people. But let’s take a step back and look at the important work at Vanderbilt University (Ricketts, Dittberner, and Johnson, 2008) and Cambridge University (Aazh and Moore, 2007). These researchers (while working independently and with speech) noted that due to severe cochlear damage, dead regions may be encountered that necessitated avoiding damaged regions. Benefits were found when this high frequency information was frequency-lowered to a healthier part of the cochlea. When their results are taken together, the following information can be gleaned (where the table is my summary of their work):
Mild Hearing Loss | 55 dB Hearing Loss | Steeply sloping audiogram |
Broad bandwidth | Narrow bandwidth | Narrow bandwidth |
For people with a mild hearing loss, a wider bandwidth is better, but for people with greater hearing loss or if the audiometric configuration was steeply sloping, “less may be more,” at least as far as bandwidth is concerned.
Frequency lowering works for speech because it’s only the higher frequency obstruents (sibilants, affricates, and fricatives) that are frequency lowered, and these all have a broad band spectral configuration. It doesn’t matter whether an [s], for example, begins its energy at 4000 Hz or 3600 Hz. There may be some confusion with other similar consonants, such as the [ʃ], but this shouldn’t be too much of an issue unless the frequency lowering is quite significant.
However, and now I am finally getting around to answering your question, the phrase “frequency lowering” and the word “music” should not be mentioned in the same sentence or even in the same room. Any alteration of the harmonic structure in music will cause dissonance. Frequency lowering should not be used in any form for music.
14. Based on some differences between speech and music, how would the hearing aid compression circuitry be set for music versus that of speech?
As you know, today, audiologists rarely “set” compression directly. Gone are the days of going to the “compression” part of the software and picking kneepoints and ratios (except for maybe a few “compression nuts” out there). Today we simply click on tabs for soft, average, and loud, and it all happens behind the scenes. But that won’t stop me from answering your question.
Like the specification of the frequency response, the specification of compression is more of a cochlear issue rather than a music versus speech issue, and like my answer to the question about frequency response, there shouldn’t be any significant difference between a speech program and a music program for the compression setting. This has been verified experimentally by several researchers, such as Davies-Venn, Souza, and Fabry (2007).
Despite having the same name “compression”, not all compression systems are similar but they have become more similar since the late 1980s when the modern form of Wide Dynamic Range Compression (WDRC) was invented. Prior to the modern form of WDRC, hearing aids were set to “avoid” compression using circuits that only became active at a rather high input level (“high level compression”) or circuits where the compression detector was frequency specific (“frequency dependent compression”). In both cases, the listener was fit with amplification that was linear over most (if not all) of its operating range.
However, with the advent of WDRC hearing aids are now able to enter its non-linear phase with inputs that are quite low. The trick with WDRC is to ensure that the compression ratio is not very high… for mild to moderate level hearing losses, an ideal compression ratio is typically around 1.7:1, but this would be the case equally for speech and for music programs.
I mentioned earlier, Kuk and Ludvigsen (2003) have published some nice data showing that if there is venting in the hearing aid system, unamplified lower frequency sound will enter the ear canal combining with the amplified sound such that the “real” compression ratio is several points lower. For example, a compression ratio of 1.7:1 is really closer to 1.3:1 with a large vent, or in some cases, even close to linear (1:1).
Of course, for more significant hearing loss, depending on the nature of the sensory damage, higher compression ratios would be required but there will be more of an issue understanding both speech and appreciating music in these situations.
15. What about listening to MP3 audio files and streamed music? I’ve heard that they are “compressed?”
What a great question- it’s as if I specifically asked it! For the answer to this we need to go back to some great research by Croghan, Arehart, and Kates (2012) who specifically looked at this issue. Pre-recorded music such as that found on a CD or a MP3 audio file in most cases, has already been compression limited at the source. Compression limiting is a relatively benign form of compression in that the waveform and spectrum is maintained in shape but is played back at a reduced sound level. Compression limiting is designed primarily to ensure that the sound levels do not exceed the capability of the music player (or radio station) rather than limiting potentially irritating or damaging outputs per se, and as such is found in virtually all MP3 like and streamed music for all listeners regardless of their hearing status.
In the case of hard-of-hearing people who wear personal amplification (with its own WDRC), the addition of a second “layer” of compression inherent in the streamed music, can be problematical. The researchers indeed found that for streamed music, a more linear (lower compression ratio) music program would be useful than for live music.
This also has ramifications for local radio stations. In my home town, there is a Jazz FM station that has great music, but the administration of that radio station was mandating the use of too much compression limiting in their output. Subsequently, many of my hard of hearing (Jazz) musicians cannot appreciate the music from that station. I have been on the phone many times with their administration and technical staff, but to date, I have not been successful in getting them to back off a bit on the compression limiting that they use… and I’m a black belt in karate, but that threat didn’t seem to help much… besides, I am only able to take on 4-year olds… the 8-year olds come after me!
Instead of having several speech programs and “one music” program, if your hard of hearing patients desire to listen to streamed or pre-recorded music, consideration should be made for having at least two music programs where the streamed music program was set to a more linear compression setting than the live music program. Some hearing aid manufacturers allow you to make this differentiation in the fitting software (if you trust their music programs).
16. How can a wireless protocol such as Bluetooth assist musicians and my other patients who want to listen to music?
Bluetooth is a wonderful wireless (and secure) protocol that can provide the hard of hearing patient with a better signal (and better signal to ratio) to hear the speech and music from a distance. Current distance limitations of Bluetooth for hearing aids are on the order of 10 meters (or a bit over 30 feet for those who still use the non-metric system… Americans, Liberians, and people from Myanmar). As long as there is a sufficiently well-designed Bluetooth emitter accessory such as a TV listening device, the signal can be routed with minimal side effect, essentially allowing the listener to use their own hearing aids as in-ear monitors while performing live.
There are some technical issues with using this approach, however such as ensuring that the accessory is up to the task of functioning as a Bluetooth emitter for this situation. In the case of a TV device, the output of the audio rack during a live performance is not as well-controlled as is the output of a television. Subsequently, a pre-amp may be required between the output of the audio rack and the Bluetooth TV device, however, pre-amps can now be purchased for less than $100 so this technical issue should not be too onerous to overcome.
Another issue is related to Bluetooth and not music per se, but Bluetooth now uses a 2.4 GHz radio frequency transmission, and while this higher rate does away with the old intermediary streamers (since the antenna is now very small), 2.4 GHz is close to the resonant frequency of body fat (which is why microwaves are also in the 2.4 GHz range). If someone walks between the Bluetooth emitter and the hard of hearing person wearing hearing aids while performing, there can be a temporary cut-out of the signal.
However, once these technical issues are ironed out, Bluetooth can allow the hard of hearing musician with the equivalent of in-ear monitors that are configured for their hearing loss and also provide level-dependent compression as required. And although Auracast™ is not yet commercially available this date), this approach can also be used, especially if an emitter is close to the performing artist and situated on the ceiling to avoid some the 2.4 GHz issues.
17. What about some of the advanced features that are found in modern digital hearing aids? Should we still enable feedback management and noise control software?
Advanced features in a music program for hearing aids can be problematic for two reasons- they may confuse music with noise, and they can add very significantly to digital delay.
In the case of feedback management, it is commonplace for this circuit to confuse a music harmonic for feedback. There are many cases where this hearing aid circuitry simply “turns off” the music. Recall that while speech is primarily lower frequency sonorant with harmonics, the harmonic levels in the higher frequency region tend to be at very lower levels and this higher frequency region is dominated by broader band sibilant sounds. This is why feedback management circuitry, when required, works well- there is minimal confusion between the feedback and the higher frequency elements of speech. But music (with the exception of percussion) is made up of low frequency and high frequency harmonics. Many feedback management circuits tend to restrict their operating range to sounds over 1500-2000 Hz, which works well for speech but still can be problematic for harmonically rich music.
In the case of noise reduction algorithms, the way they function is by assessing the environment and then again at some short time period later. Hearing aids that purportedly have a digital delay of less than 1 msec on their specification sheet, can have actual digital delays on the order of 8-10 msec with a noise reduction algorithm being implemented.
These are the primary two issues of why most advanced features should be minimized (or if possible, disabled) for any of the music programs.
18. This has been a lot of great information. Can you summarize exactly what a music program should look like?
Sure. A music program should be similar to a speech-in-quiet program with similar frequency response and similar compression characteristics but also have advanced features disabled. In addition, the input related sounds for the music program (and indeed for all programs) should be able to handle the higher-level inputs associated with music without distortion. That is, the analog to digital conversion part of the digital signal processing should have a sufficiently high enough range such that music can be digitized without distortion.
19. Is there some way to alter the nature of the music even before it is received by the hearing aids?
Over the years, there have been some ingenious approaches to providing “altered music” for the hard of hearing child. Given that, in most situations, there is better low frequency acuity than in the higher frequency region for many children with congenital or early-acquired hearing loss, a bass clarinet can be used in the recording of music instead of a violin or piccolo. Here is an audio file with this very issue.This is a commonly heard children’s song, but with musical instruments that have their playing range in an audiometric region where these children may have better acuity.
Another common area of concern I receive is from hard of hearing musicians who attend Colleges of music where, as part of their accreditation, ear training courses must be taken and passed. I had a recent student who was an amazing mezzo-soprano but, due to chemotherapy as a youngster, had a high frequency hearing loss above 1000 Hz. She could not pass her interval training portions of her classes. Intervals are spacings in music that are quite important and typically contribute to the harmonic richness of music without being dissonant. These may include intervals such as an octave, a fifth, a minor third, and so on. A solution was to contact the school administration and arrange for the interval testing to be performed two octaves lower on the piano keyboard where they could be heard in a region where this student had better acuity. Her mark incidentally went from 26% to 86%.
20. Do we now know everything we need to know about setting a music program (or programs) in hearing aids?
What a timely question. Indeed there are a number of still-to-be-performed studies that can add substantially to the clinical and research knowledge in the domain of music and hearing aids. A recent article in HearingReview.com called “What we still don’t know about music and hearing aids.” (Chasin, 2023) reviews ten unanswered but simple to answer (Capstone-research-caliber) questions about music and hearing aids. More information can be found at Chasin (2023) or Chasin (2022). Here is a listing of ten such studies, each of which can provide important clinically-relevant information:
Study 1: A commonly asked clinical question is, “What is the best musical instrument for my hard of hearing child?” Are harmonic rich musical instruments better than ones with fewer auditory cues?
Study 2: Is multichannel compression a good idea for a music program, or for that matter, an in-ear monitor system?
Study 3: Is multi-channel compression less of an issue for some instrument groups than others?
Study 4: Can we derive a Musical Preference Index like we have the SII for speech?
Study 5: For music, would a single output stage and receiver be better than many?
Study 6: Does the optimization of the front-end analog-to-digital converter for music also have benefits for the hard of hearing person’s own voice?
Study 7: Given cochlear dead regions, would gain reduction be better than frequency lowering, which alters the frequencies of the harmonics?
Study 8: Since “streamed music” has already been compression limited (CL) once during its creation, a music program for streamed music should have a more linear response than for the speech-in-quiet program.
Study 9: Research has found that with cochlear dead regions, people with high frequency sensorineural hearing loss find that speech and music sound “flat”. Would people with a low frequency loss find that speech and music sound “sharp”?
Study 10: Is there a more clinically efficient method than the TEN (HL) test which will only take seconds rather than 8-10 minutes to determine cochlear dead regions?
References
Aazh, H., & Moore, B. C. (2007). Dead regions in the cochlea at 4 kHz in elderly adults: relation to absolute threshold, steepness of audiogram, and pure-tone average. Journal of the American Academy of Audiology, 18(02), 097-106.
Chasin, M. (2006). Can your hearing aid handle loud music? A quick test will tell you. The Hearing Journal, 59(12), 22-24.
Chasin, M. (2012). Okay, I’ll say it: Maybe people should just remove their hearing aids when listening to music. Hearing Review, 19(3), 74.
Chasin, M. (2022). Musicians and Hearing Loss. Plural Publishing.
Chasin, M. (2023). What we still don’t know about music and hearing aids. Hearing Review.
Chasin, M., & Hockley, N. S. (2014). Some characteristics of amplified music through hearing aids. Hearing Research, 308, 2–12.
Chasin, M., & Russo, F. (2004). Hearing aids and music. Trends in Amplification, 8(2), 35–48.
Cornelisse, L. E., Gagne, J. P. & Seewald, R. C. (1991). Ear level recordings of the long-term average spectrum of speech, Ear and Hearing, 12(1), 47–54.
Croghan, N. B. H., Arehart, K. H., & Kates, J. M. (2012). Quality and loudness judgments for music subjected to compression limiting. Journal of the Acoustical Society of America 132, 1177–1188.
Davies-Venn, E., Souza, P., & Fabry, D. (2007). Speech and music quality ratings for linear and nonlinear hearing aid circuitry, Journal of the American Academy of Audiology, 18(8), 688–699.
Kuk, F., & Ludvigsen, C. (2003). Reconsidering the concept of the aided threshold for nonlinear hearing aids. Trends in Amplification, 7(3) 77–97.
Moore, B. C. J., & Tan, C-T. (2003). Perceived naturalness of spectrally distorted speech and music. Journal of the Acoustical Society of America, 114(1), 408–419.
Moore, B. C. J., Füllgrabe, C., & Stone, M. A. (2011). Determination of preferred parameters for multichannel compression using individually fitted simulated hearing aids and paired comparisons. Ear and Hearing, 32(5), 556–568.
Mueller, H.G., Stangl, E., Wu, Y-H. (2021). Comparing MPOs from six different hearing aid manufacturers: Headroom considerations. Hearing Review, 28(4): 10-16.
Oeding, K., & Valente, M. (2015). The effect of a high upper input limiting level on word recognition in noise, sound quality preferences, and subjective ratings of real-world performance. Journal of the American Academy of Audiology, 26(6), 547–562.
Plyer, P., Easterday, M., & Behrens, T. (2019). The effect of extended input dynamic range on laboratory and field-trial evaluations in adult hearing aid users. Journal of the American Academy of Audiology, 30(7), 634–648.
Ricketts, T. A., Dittberner, A. B., & Johnson, E. E. (2008). High frequency amplification and sound quality in listeners with normal through moderate hearing loss. Journal of Speech-Language-Hearing Research, 51, 160–172.
Skinner, M. W., & Miller, J. D. (1983) Amplification bandwidth and intelligibility of speech in quiet and noise for listeners with sensorineural hearing loss. Audiology, 22(3), 253–279.
Yellamsetty, A., Ozmeral, E., Budinsky, R., and Eddins, D. (2021). A comparison of environmental classification among premium hearing instruments. Trends in Hearing, 4,1-14.
Citation
Chasin, M. (2023). 20Q: optimizing hearing aid processing for listening to music. AudiologyOnline, Article 28684. Available at www.audiologyonline.com

